Guide
Web Application Architecture: Tutorial & Examples
Table of Contents
Modern web applications vary widely in complexity, from simple, content-based websites to robust and complex multimedia applications. With this variation comes a wide diversity of architecture styles and development approaches, all with the goal of delivering performant, reliable products that meet user expectations and business demands.
To keep pace with evolving development approaches and business requirements, modern engineering teams must understand different web application architectures and the best practices and tradeoffs associated with them. Doing so helps teams choose appropriate architecture styles and make well-informed design decisions that benefit the product in the short and long term. In this article, we provide practical guidance on how to design web applications by examining four popular types of web application architectures, their tradeoffs, and their practical use cases.
Summary of key web application architecture concepts
The table below summarizes the four types of web application architectures covered in this article.
| Architecture type | Use case | Description |
|---|---|---|
| Static website | Company website | Static websites often rely on a simple client-server implementation or a content management system to simplify development and deployment. |
| Monolithic | Small web application, such as local library management | Monolithic applications are contained in a single deployed service. This simplifies inter-component communication and application deployment but can lead to scalability issues. |
| Microservices | Complex application serving a large user base, such as an e-commerce platform | Microservice architectures divide responsibilities between independently scalable services to handle high or variable loads. |
| Serverless | Event-driven web applications, such as an IoT backend | Serverless applications rely on a cloud provider to automatically manage server infrastructure, scaling, and maintenance. |
Static website web application architecture
While purely static websites cannot meet all modern business needs, they remain widely used for specific purposes like documentation, blogs, and simple landing pages. Content on static websites does not change in response to user behavior and can be updated by modifying source files or through build processes integrated with content management systems. Static websites do not perform server-side processing or dynamic content generation. Rather, they deliver fixed, pre-written content to users directly from the server.
Static sites are implemented by creating pre-rendered files (HTML, CSS, JavaScript, and media). These files are uploaded to a web server or a specialized hosting platform and served directly to users without requiring server-side processing. Companies may choose to utilize a combination of content management systems (e.g., WordPress, HubSpot CMS), static site generators (e.g., Gatsby, Hugo), and static file hosting services (e.g., AWS S3 + Cloudfront, GitHub Pages) to simplify updates and create build and deployment pipelines.


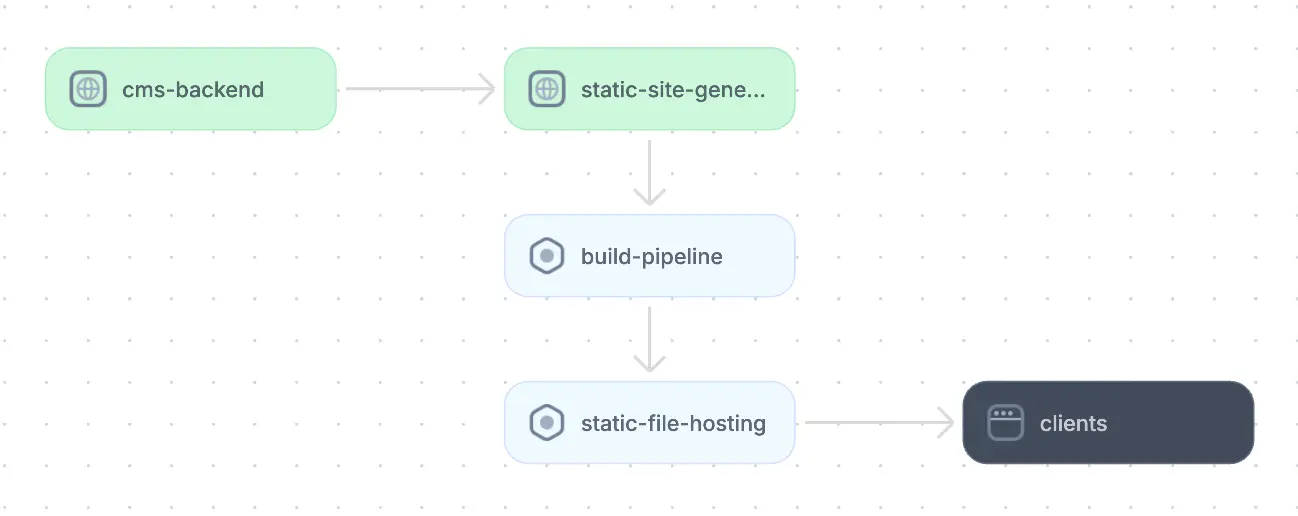
An example of a static web application architecture
Monolithic web application architecture
As stated above, most businesses require functionalities that a static website alone cannot provide. In the modern web, dynamic capabilities like authentication, authorization, user management, CRUD (create, read, update, delete) transactions, and third-party integrations have become nearly ubiquitous.
As these dynamic features have become the norm, web application backends have grown in complexity to accommodate interactive and data-driven features. Modern engineering teams must therefore select a suitable architecture for their use case that handles the expected user load and accommodates the development of new features. For many startups and small-to-medium-sized businesses, a monolithic architecture is a common place to start.
Monolithic design pattern
A monolithic application is characterized by a single, tightly integrated codebase that contains all components and is deployed as a single unit. A traditional web application's monolithic architecture includes layers for the client-side user interface, business logic, data storage, integration with internal and external APIs, security, and logging and monitoring.


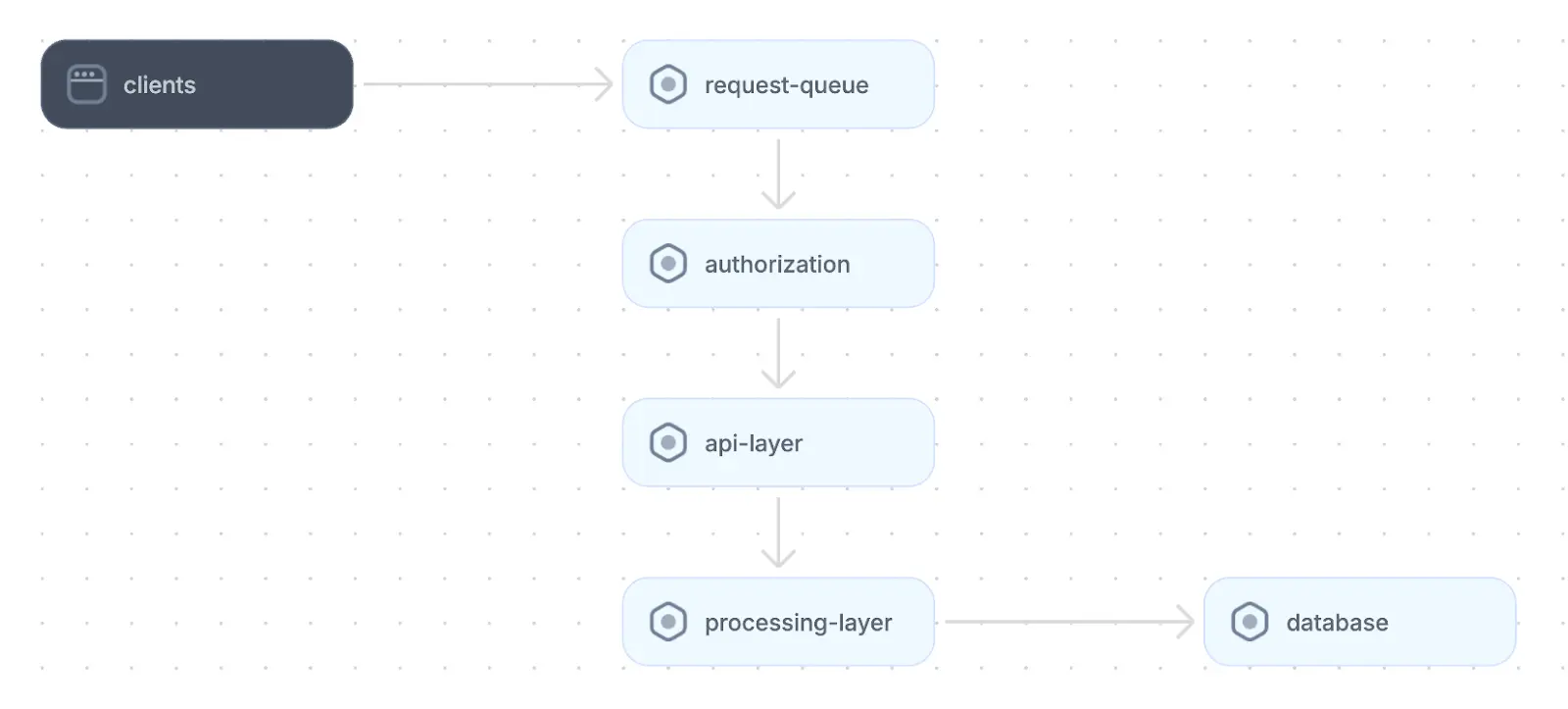
An example of a monolithic web application architecture
While a monolith is–by definition–built and deployed as a single unit, this does not mean there can be only one server and one database. Multiple instances of a monolithic application can be distributed across two or more server processes for improved redundancy and scalability. In these cases, teams implement load-balancing strategies to route traffic between server instances. Many monoliths also use multiple databases for sharding or other forms of data segmentation.
Benefits
While the tradeoffs of any application architecture are highly context-dependent, certain advantages of monolithic architectures apply across a variety of use cases.
Data consistency
Handling transactions and ensuring data consistency within a monolithic application is relatively simple because all business logic is performed within tightly coupled components that typically do not need to communicate over a network. Data consistency is most easily achieved in monoliths that utilize only a single server process and a single database. When multiple server or database instances are deployed, this added complexity can introduce atomicity, concurrency, latency, and other issues similar to those found in distributed systems.
Early-stage development velocity
Monoliths’ centralized nature, relative simplicity, and ease of deployment mean that features can be built and released quickly without the overhead of managing a distributed system, network communication, or service boundaries. Monoliths also generally require less upfront design than distributed applications, which further reduces time to market.
Low latency
Components within distributed systems must communicate with one another through network requests. Monoliths avoid this latency because their components are colocated. In addition, latency in a monolithic application can be further lowered through several strategies, such as:
- Optimizing the efficiency of application code (e.g., choosing efficient algorithms and data structures, avoiding blocking operations like synchronous I/O and network calls, etc.)
- Implementing caching mechanisms for frequently accessed data or computationally heavy calculations
- Utilizing CDNs for static assets
- Improving database query performance by optimizing SQL queries or using indexed columns for frequent lookups and joins
Challenges
Many benefits of monolithic web application architectures stem from monoliths’ centralized nature and relative simplicity. However, as monolithic applications grow, scaling challenges tend to emerge.
Scalability
Monoliths can be scaled horizontally or vertically, but both techniques have tradeoffs.
Increasing a monolithic server or database’s capacity (scaling vertically) becomes cost-prohibitive beyond a certain point, and there are physical limits to how much a single machine can be upgraded. In addition, relying solely on vertical scaling introduces practical constraints, such as possible downtime when making server updates and potentially introducing a single point of failure in the system.
Deploying multiple server instances, load balancers, or multiple databases (scaling horizontally) can be impractical in a monolithic application for two reasons. First, the added complexities of load balancing, redeploying multiple application instances with every change, and ensuring data consistency undermine a primary monolith benefit: simplicity. Additionally, because the entire monolith must be duplicated to scale any part of the application, components are needlessly replicated, overconsume resources, and increase costs.
Development issues
While early-stage development of monolithic applications is typically more rapid and leads to faster time to market, the size, tight coupling, and complexity of monolithic codebases can lead to a number of development inefficiencies as the system grows. Some of these issues include:
- Cascading effects: Changes or errors in one part of the application may inadvertently impact other areas, which makes the system more fragile and harder to update and debug.
- Long build and test times: Monoliths are built and deployed as a single unit. Therefore, it is usually necessary to create a new build and test the entire system for each change, however trivial. As a result, development speed decreases.
- Inability to develop in parallel: Multiple teams or developers working on the same monolithic codebase can experience merge conflicts and unintentionally blur lines of functional responsibility between modules and components.
- Steep learning curves: Contributions to a monolith often require knowledge of the entire system. However, when the codebase grows beyond a certain threshold, it becomes increasingly difficult to onboard new developers and for all team members to understand the application enough to perform their job duties. This problem is significantly exacerbated when the application lacks sufficient documentation.
Full-stack session recording
Learn more





Recommendations
If your team is experiencing many of the drawbacks above, it is worth considering whether a monolithic application is still the best choice for your organization. However, how and when to transition away from a monolithic architecture is a significant long-term decision that should be carefully considered.
A key step is to gain visibility into your system using tools like Multiplayer’s system dashboard and full stack session recordings. These features allow your team to quickly and efficiently gather the right information to evaluate the current state of your system and make better-informed decisions.
Once you have gained this visibility, identify the root causes of issues and determine whether architecture is truly the core problem. In some cases, practices like improving communication channels, writing adequate documentation, optimizing the existing architecture, or improving development workflows can mitigate issues without abandoning the current architecture. Even if rearchitecting is necessary, this reflection will likely identify other opportunities for improvement.
In addition, consider the realities of transitioning to and maintaining a different architecture. Consider the time, costs, and expertise required to implement the architecture, including steps like adopting new DevOps practices, learning new tooling, and setting up monitoring and logging. Ensure your team has the necessary skills and experience to succeed before making such a substantial investment.
Finally, if it is time for a transition, start small and create a plan for incremental changes. Prioritize the most critical parts of the system by examining factors like performance, importance to business goals, development issues, and error rates. Allow sufficient time for rearchitecting to be performed thoughtfully.
Microservices-based web application architecture
While monolithic architectures can simplify initial application implementations, their tightly coupled nature often causes problems once the codebase or user traffic grows beyond a certain threshold. This threshold differs depending on the organization or nature of the application.
As discussed previously, common factors that make monolithic architectures impractical are their limited scalability, cost inefficiencies, development issues, and difficult long-term maintainability as the codebase grows. A microservices web application architecture helps development teams address these challenges.
Microservices design pattern
The microservice design pattern involves breaking up the backend system into independent services, each responsible for a distinct part of the overall functionality. In most microservices architectures, an API gateway acts as a unified client entry point and routes requests to the appropriate microservice. Each service processes its own requests in isolation, often asynchronously using a request queue. This decoupling allows the system to process multiple requests in parallel.


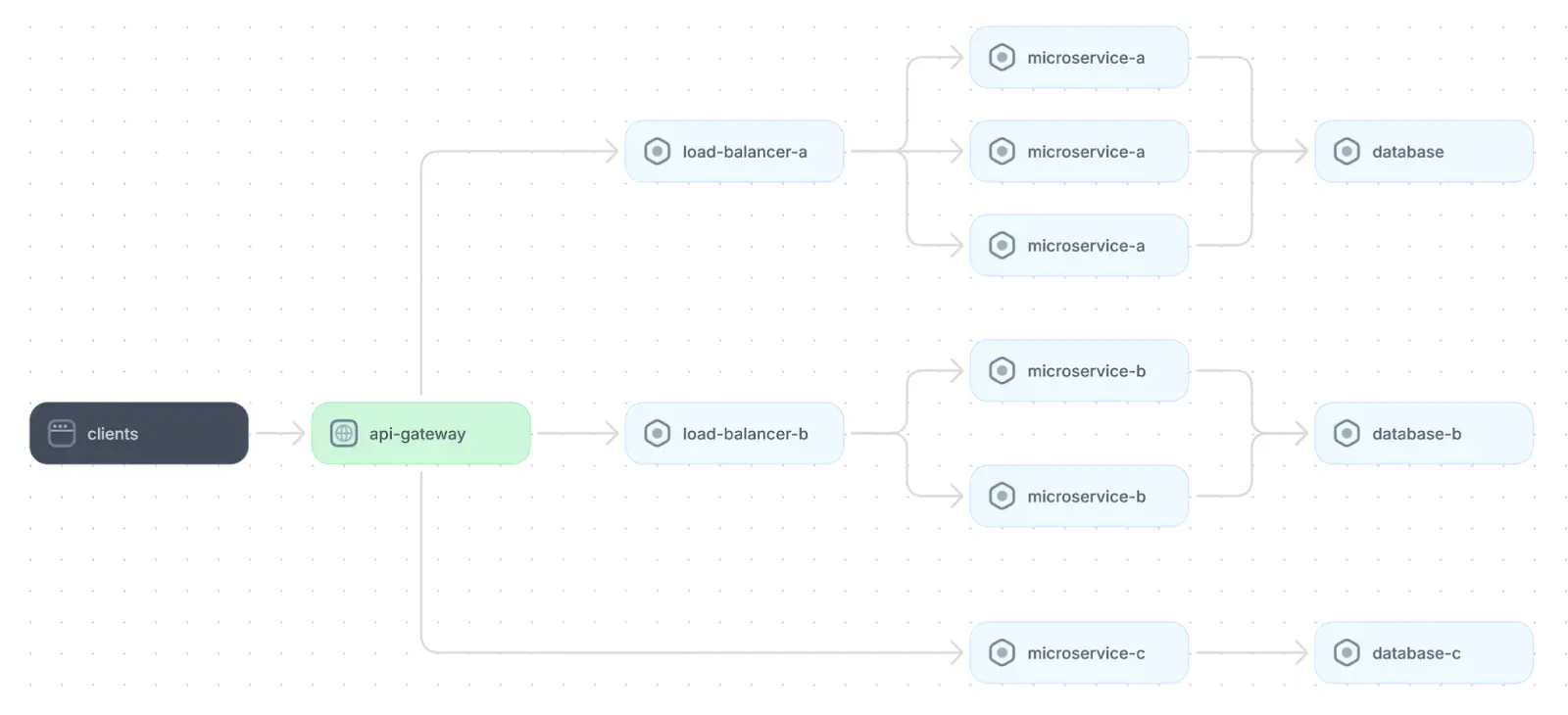
An example of microservices web application architecture
Individual microservices are autonomous, meaning they can be developed, updated, deployed, and scaled independently from other services. While several different approaches to interservice communication exist, microservices architectures typically favor lightweight protocols like HTTP, HTTPS, and message queue protocols.
Benefits
Engineering teams that implement effective microservice architectures gain the following benefits.
Performance and resource utilization
Microservices facilitate parallel processing of requests, which improves overall application performance. In addition, microservices can scale independently of each other. This leads to more efficient resource utilization because only those services that experience a high load can be assigned more resources without scaling other portions of the application.
Long-term development efficiency
Each service being designed as an independent unit offers several development advantages. Services can be developed using their own internal protocols, technologies, and programming languages optimized for that service’s functionality. In addition, different teams can develop independent services in parallel. As long as a service’s communication interface is preserved, teams can update a service without updating other system components.
Compartmentalization
Since microservices are effectively smaller-scale applications responsible for a subset of the overall application functionality, each microservice can be treated as a separate system. This leads to smaller codebase sizes, which makes each service easier to understand, update, and test compared to large monolithic codebases. It also simplifies onboarding, as new developers can focus on their own service’s functionality without the need to understand the low-level implementation details of other services.
Streamlined deployments
Microservices simplify deployment and upgrade of application backends because each service can be versioned and upgraded separately. Proper load balancing and API versioning implementations can also enable multiple versions of a given service to coexist, facilitating enhancements like blue-green deployments for individual services. As a result, teams benefit from controlled upgrades and less downtime in case of issues.
Interact with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
Challenges
As with other engineering decisions, adopting microservices introduces challenges that must be addressed to ensure positive outcomes.
Service independence
Service independence can cause system problems if teams do not strategically implement microservices. For example, if data boundaries between services are unclear, data inconsistency can quickly become a significant problem.
Failure diagnosis
The decentralized nature of microservice deployments can make it very challenging to trace system failures to their root cause. In addition, a failure caused by one service can cascade through the system and lead to a large-scale outage before it is discovered.
Communication
Microservice communication happens over internal backend networks. This requires network management as part of the server development process, including factors like bandwidth management, handling internal traffic load, and protecting services from vulnerabilities.
Authentication
Authentication and authorization become much more complex since each service is also an actor in the system and requires technical controls for access rights to data and other services.
Recommendations
As with any architectural choice, teams should carefully evaluate the pros and cons of microservices architectures and their business requirements before implementing this web application architecture. Factors such as functionality, expected user load, long-term growth, and maintainability are essential in the evaluation process.
Development teams should ask these questions as they evaluate tradeoffs:
- Is the application expected to grow significantly in terms of features, users, or data?
- Does the project require the ability to scale different parts of the application independently?
- Do engineering teams have the time and skills needed to adopt this architecture successfully?
- Does your organization have the resources to manage the added complexity of a microservices architecture (e.g., monitoring, deployment, debugging)?
- Are there any compliance or security issues that need to be considered?
If the answers to these questions point toward a microservices architecture, teams should consider several important implementation details. Let’s take a look at four of them.
Microservice communication
The internal network of a microservice backend is one of the most critical parts of the system. All system functionality that relies on multiple microservices is dependent on this communication framework. Therefore, the protocol chosen for interservice communication must be reliable, fast, and efficient.
REST (or REpresentational State Transfer) is a very common communication paradigm. Originally designed as a way to clearly define interfaces between the backend and the client. REST is based on standard HTTP methods, stateless, and very simple to define.
RPCs (Remote Procedure Calls), a mechanism of direct function invocation across a network, are another type of protocol popular in microservice communication. The most common RPC framework is gRPC, developed by Google and often used for fast, lightweight communication and high-performance streaming applications.
No matter which communication protocol is chosen, each microservice must clearly define its interface so other services can communicate with it without worrying about its internal implementation details. For REST applications, this can be achieved by using the OpenAPI Specification to document endpoints, request and response formats, and errors. In gRPC, this is achieved using Protocol Buffers.
syntax = "proto3";
service UserService {
rpc GetUser (GetUserRequest) returns (GetUserResponse);
}
message GetUserRequest {
string user_id = 1;
}
message GetUserResponse {
string user_id = 1;
string name = 2;
string email = 3;
}Example gRPC Protocol Buffer, defined in a .proto file
Message queues like Kafka and Redis can also be used for asynchronous communication between microservices. In this model, a service publishes a message to a given queue without being aware of which, or even how many, microservices will process it.
Data boundaries
It is crucial for microservices to define data ownership and respect these boundaries to avoid inconsistency issues. This can be done in a number of ways.
For example, each microservice can be responsible for a part of the schema within a single database server. Other services should not read or write this data directly, even if they have access to the database. Instead, they must interact with the data through the governing service's APIs.
Alternatively, database deployments can be aligned to the microservice ownership. In this approach, each individual service manages its own separately deployed database. This allows database servers to scale more easily but requires careful management to ensure data consistency, high availability, and fault tolerance.
Fault tolerance and monitoring
Since each microservice is independent, there is no central place to monitor system health and detect failures. In addition, each service becomes a separate point of failure and can cause cascading issues in the entire system if failures are not handled gracefully. Therefore, it is essential to design services to tolerate failures predictably and in a way that will not disrupt the functionality of other services. One way to achieve this is to implement service redundancy so that each service has fallbacks in place if and when one instance becomes unreachable or crashes.
Continuously monitoring the system is also very important. Each service can be designed with a "heartbeat" or health-check API, which a monitoring service calls regularly to verify its health. Developers can build separate interfaces for operations teams to monitor the system using these APIs. Design patterns like retries, back off, and circuit breakers allow systems to detect and respond to failures automatically.
One click. Full-stack visibility. All the data you need correlated in one session
RECORD A SESSION FOR FREEDefining system architecture
System-wide behavior and architecture can be hard to define and track in a microservices-based application. This is because the system is an amalgamation of many subsystems, each with its own internal implementations, design patterns, and deployments. The sheer complexity of microservices architectures often makes these applications difficult for developers, operations teams, and stakeholders to comprehend in their entirety. Additionally, because independent development teams typically maintain separate services, knowledge silos can emerge.
Therefore, organizations must clearly define expectations for the overall system so that the individual teams working on the separate services have clarity on their role and the broader system. As the application evolves, architectural and interface definitions must be tracked to prevent architectural drift and ensure all teams have access to up-to-date information.
Serverless web application architecture
Serverless applications represent a completely different paradigm than monoliths or microservices. When developing serverless applications, developers write small, single-purpose functions that are executed on demand in response to events. These functions are hosted on a cloud platform, and the cloud provider manages all of the underlying infrastructure required to execute each function.
Serverless architecture
Event trigger mechanisms are the fundamental concept behind serverless web application architecture. Multiple event sources, such as API calls to an API gateway, external events from IoT sensors, and events raised by other cloud infrastructure components, can trigger an event. Each event leads to the execution of a given function with the specific event details passed as a parameter, and each function behaves like an asynchronous API call.


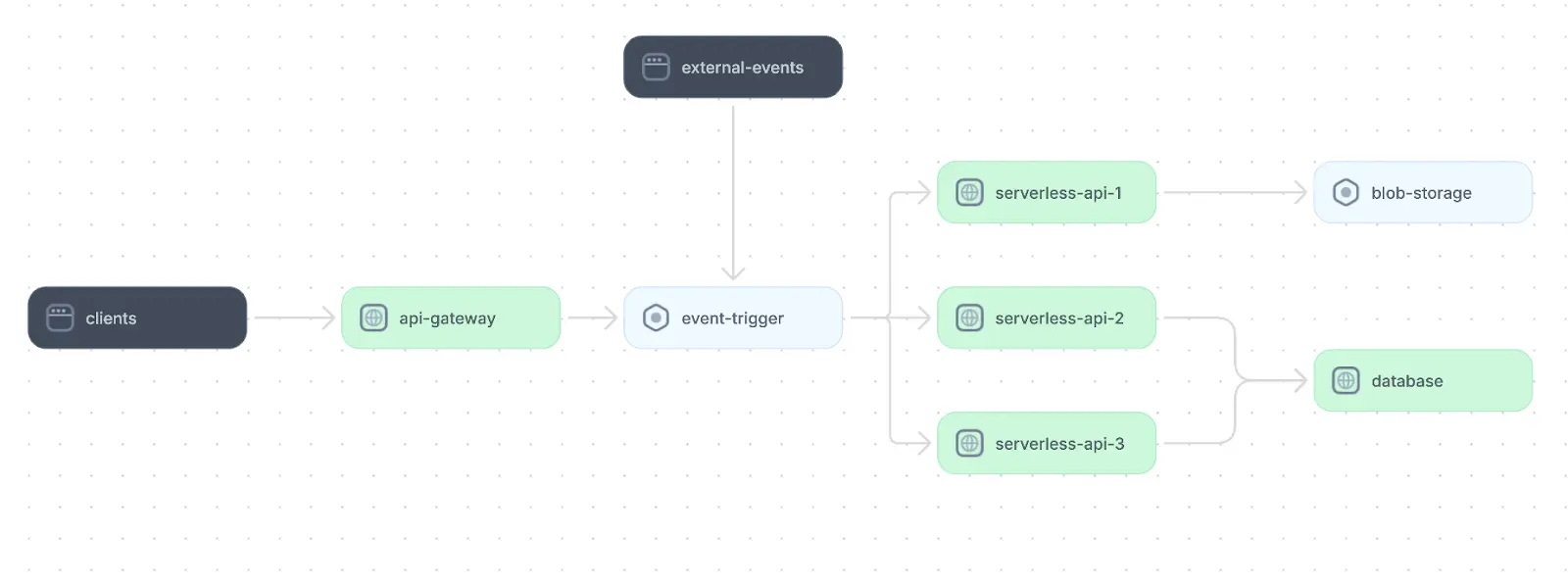
An example of serverless web application architecture
Benefits
Provisioning resources for an application that serves a large, geographically dispersed user base is not trivial. It involves numerous decisions regarding scaling strategies, load balancing, latency optimization, fault tolerance, etc. While serverless architectures do not entirely remove these complexities and still require decisions on configuring infrastructure, the serverless model intends to ease this process significantly. Here are three benefits of serverless architectures.
Scalability and cost efficiency
A key feature of serverless architectures is their pay-as-you-go model, meaning that organizations only pay for resources consumed during function execution. In addition, serverless providers handle the allocation of resources in response to changes in user traffic. This means that individual functions are automatically and independently scalable with little or no need for manual configuration. These two benefits are most significant for applications with low, concentrated, or unpredictable traffic.
High availability
In the serverless model, cloud providers handle redundancy and failover mechanisms automatically. Serverless platforms typically provide service level agreements (SLAs) for the underlying cloud services that store data and provide infrastructure. These SLAs typically guarantee 99.95-99.99% uptime, which is sufficient for most use cases.
Development velocity
Reducing the overhead of infrastructure management and scalability as core concerns can significantly speed up the development process by allowing developers to focus on writing application code. In addition, most serverless platforms are built with dedicated solutions for common development needs like security and CI/CD.
Challenges
Many challenges of serverless architectures stem from the limitations imposed by the serverless provider’s predefined services and infrastructure. Let’s explore a few of these drawbacks.
Customizability
Since serverless platforms abstract away much of the underlying infrastructure, developers have limited control over specific server configurations. Serverless architecture, therefore, limits developers' ability to fine-tune performance parameters to the same degree as other web application architectures. For example, AWS Lambda currently allows a maximum memory allocation of 10 GB and a maximum execution time of 15 minutes. These are hard limits, so any application with requirements beyond these limitations would likely need to parallelize workloads, which adds complexity and potentially negates the benefits of using a serverless architecture in the first place.
Cold starts
The downside to provisioning resources on an as-needed basis is that resources must be reallocated to invoke a function after a period of inactivity. Reallocating resources means that the serverless provider must:
- Start a new container or virtual machine.
- Load the function's code and runtime environment.
- Initialize dependencies, such as libraries or database connections.
The speed with which these steps are performed depends on various factors, including the function’s size, programming language, configuration, and runtime. Measures like provisioned concurrency, reducing function size, and using edge functions can mitigate cold start issues.
Vendor lock-in
Serverless applications’ reliance on proprietary solutions makes switching providers a complex and daunting task. Building a serverless application involves integrating deeply with the chosen provider’s ecosystem with unique configurations, APIs, and workflows that are not easily transferable to other platforms. Significant code and architecture changes are necessary if an organization wishes to adopt a multi-cloud strategy, change serverless providers, or transition to a server-based architecture.
Recommendations
A serverless architecture is often suitable for applications that see variable volumes of requests. Examples of such applications are IoT-sensor and event-based applications that need to monitor detected events at sub-second intervals, assuming that these applications’ data processing requirements align with the chosen provider’s performance parameters. When implementing a serverless architecture, it is crucial to consider the three factors below.
Stateless execution
A key consideration when designing serverless applications is to ensure all functions are stateless. This means that they are self-contained, do not retain any information between executions, and depend entirely on external databases and event details to gain context about their activities. While traditional server environments are often stateless to some extent, the ephemeral nature of serverless functions (and their underlying infrastructure) essentially requires serverless application developers to follow this best practice.
Resources and execution time
Resources and execution time also constrain serverless functions. To ensure scalability, control costs, and guarantee fair usage of shared infrastructure across all users, cloud providers assign each serverless function a strict execution deadline, after which it can be forcefully evicted without regard to its completion status. However, there is almost no limit to how many of these executions can be executed in parallel. Because of this, it is important to optimize serverless functions to work within these constraints.
This includes:
- Optimizing function code to perform computations efficiently.
- Breaking long-running tasks into smaller, discrete functions.
- Orchestrating time-intensive tasks using tools like AWS Step Functions, Azure Durable Functions, or Google Workflows.
- Offloading heavy processing to background jobs via queues or pub/sub systems.
Monitoring and logging
The transient nature of serverless execution instances makes tracking server performance and failed requests challenging if sufficient monitoring and logging are not in place. Ensure that your application includes mechanisms for logging key events in a consistent, structured format and monitoring metrics like total function invocations, execution duration, error rates, memory and CPU usage, and costs.
Cloud providers have developed specialized tools (e.g., Amazon CloudWatch, Azure Application Insights, Google Cloud Logging) for this purpose, which teams should use to increase visibility. Importantly, organizations should prioritize the implementation of logging and monitoring from the beginning of the project to facilitate debugging during development and provide baseline points of comparison as the application grows.
When each of the above practices is in place, developers can effectively leverage the massive scale of cloud infrastructure to handle large variations in load in a performant and cost-efficient manner.
Navigating architectural complexity
Regardless of which architecture you select, the process of implementing a new system or migrating from one architecture to another is an arduous task. The biggest challenges often aren’t purely technical; they’re organizational and cognitive. As applications evolve and their logic becomes distributed across components, services, or functions, understanding how everything fits together becomes exponentially harder. Teams must learn to operate in an environment where no single person (or even team) may have complete knowledge of the system’s behavior.
To succeed, organizations need practices that make this complexity legible. Before beginning the process, establish and document how components should interact across the application, including how a user action at the frontend translates into API calls, data operations, and downstream events. As you begin to develop, observe runtime behavior to validate architectural decisions, prevent architectural drift, and catch bugs before they surface in production or escalate to wider systemic issues.
Tools like Multiplayer’s full stack session recordings can assist in this process by correlating frontend events to backend telemetry and helping developers trace a single user request from the frontend through multiple backend services and data stores. This kind of visibility helps validate assumptions about system boundaries, uncover performance bottlenecks, and surface dependencies that might not be evident from code or logs alone. When integrated with AI-assisted development tools, session data can also provide richer context for improving suggestions, debugging issues, or understanding how the system behaves under real workloads.


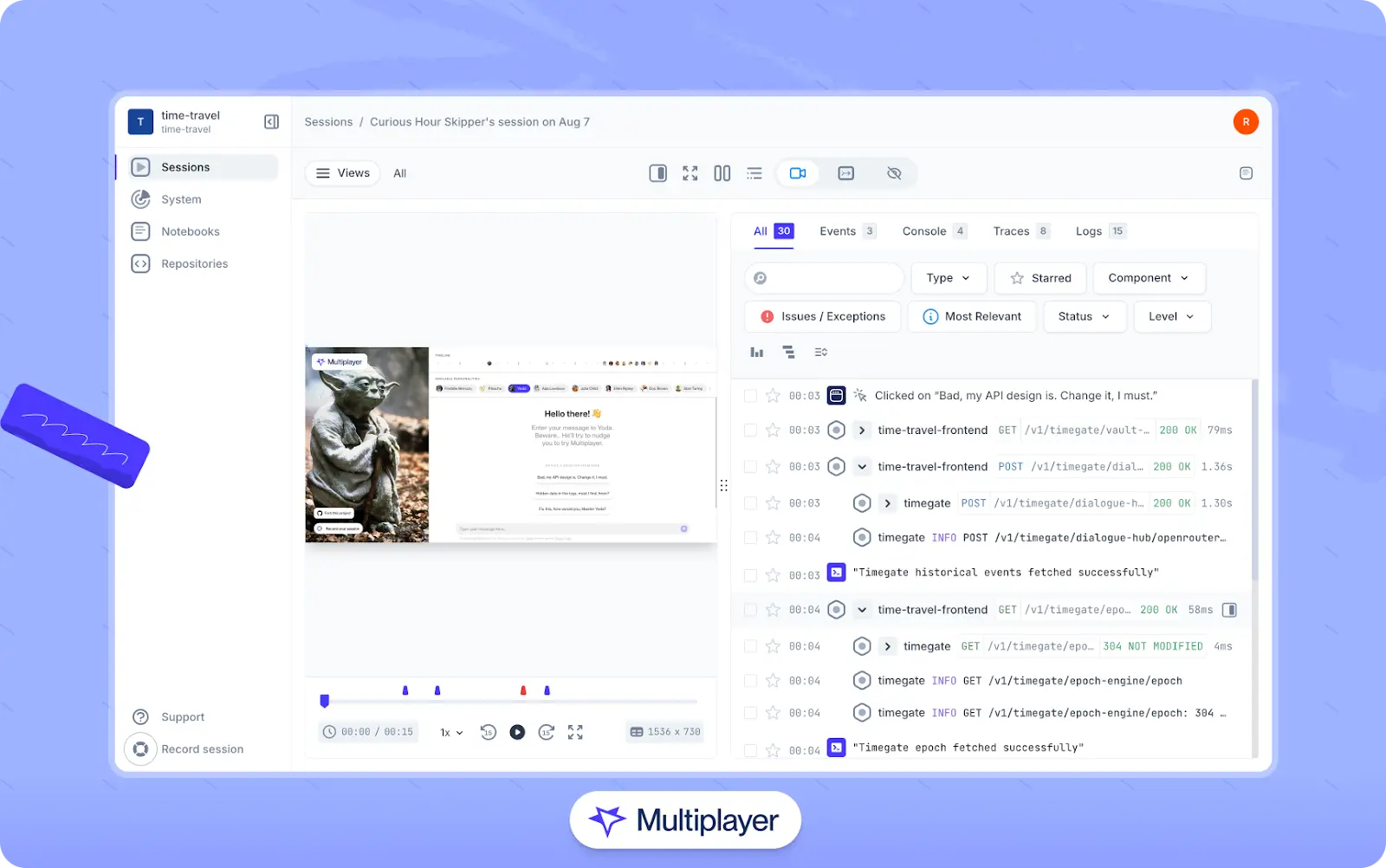
Multiplayer full stack session recordings
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREESession recordings can be useful documentation in and of themselves. However, to capture artifacts like system requirements, design decisions, and architectural decision records alongside API calls, code snippets, and step-by-step instructions, teams can use Multiplayer notebooks. The tool combines enriched text with executable code and API blocks to help developers reason about behavior, reproduce issues, and collaborate across teams. To reduce the overhead of writing and maintaining documentation, notebooks can be generated from natural language with AI assistance or automatically created from a full stack session recording.
Last thoughts
Modern web applications span a wide variety of use cases, complexities, and scales. There is no one-size-fits-all architecture for every system. Modern web application architectures like monolithic, microservices, and serverless help solve design challenges in different ways and come with unique tradeoffs.
No matter which architecture your team adopts, understanding how all components interact is critical. Clear documentation and visualizations help capture this knowledge and make it easier to reason about dependencies, identify bottlenecks, and onboard new team members. Tools like Multiplayer can help by combining architecture diagrams with insights from actual system behavior, ensuring that your architectural knowledge stays accurate and actionable as your application evolves.