Guide
Technical Debt Examples & Tutorial
Table of Contents
Technical debt often arises when development teams opt for expedient solutions, prioritizing immediate delivery over long-term maintainability. While sometimes necessary, these decisions can lead to significant future challenges. Understanding how technical debt manifests in real-world scenarios is required to develop strategies to manage and mitigate it.
This article explores technical debt through practical examples, including those faced by X (formerly Twitter). It analyzes specific technical debt issues, their underlying causes, and strategies that can be implemented to address them. Examining these issues provides actionable insights into how technical debt impacts organizations and how to manage it.
Summary of key concepts related to technical debt
| Concept | Description |
|---|---|
| What is technical debt? | Technical debt refers to suboptimal coding practices, design decisions, or documentation within an application or project. It can occur due to a multitude of factors across the software development process and can affect development velocity, code quality, system performance, and the application's long-term maintainability. |
| Intentional and unintentional technical debt | Technical debt can be classified as intentional or unintentional. Intentional debt occurs when teams knowingly compromise on quality to meet deadlines, while unintentional debt arises from lack of awareness, experience, or evolving requirements. |
| Technical debt types | Types of technical debt include architectural debt, code-level debt, test debt, and documentation debt. Each represents a different set of shortcuts or system compromises. |
| Real-world technical debt example | X (formerly Twitter) incurred technical debt due to various factors, such as changing architecture styles, the technical constraints of different tools and frameworks, and engineering team layoffs. |
| The role of AI | AI coding tools can help reduce technical debt by automating tasks and generating recommendations, especially when informed by real system context. |
What is technical debt?
Technical debt refers to the future costs and challenges that arise from intentional or unintentional development decisions. Although technical debt is sometimes presented as a product of a development team's laziness or negligence, the reality is usually far more complex. In most cases, technical debt is the result of a combination of collective factors that arise for different reasons and across different stages of the development lifecycle.
For example, technical debt may result from a calculated decision to defer technical complexities for the sake of progress toward business requirements. It may arise because business requirements evolve in unexpected ways or because the development team is asked to build features in unfamiliar languages or frameworks without adequate training. In the complex, fast-paced world of software development, it is often difficult to attribute technical debt to any single cause.
Like financial debt, where borrowing money incurs interest, technical debt accumulates “interest” in the form of increased maintenance efforts, difficulties in adding new features, and the potential for more significant issues.
The accumulation of technical debt hinders a project's success. While shortcuts might seem efficient in the short term, the long-term consequences can be severe. As technical debt grows, it creates a ripple effect throughout the system. It impairs the development lifecycle, affecting everything from the speed of new features to the overall stability of the system.
Here are some typical consequences of technical debt:
- Decreased development speed: As technical debt grows, it becomes harder to implement changes or add new features, slowing down overall development.
- Increased costs: Addressing technical debt requires significant time and resources, leading to higher long-term costs.
- Reduced software quality: Quick fixes and poor design decisions can lead to bugs, inefficiencies, and lower software quality.
- Potential system failures: Accumulated technical debt can make systems fragile and prone to failure, especially when they are under stress or as they scale.
Intentional and unintentional technical debt
Technical debt manifests in various forms throughout the software development process. Broadly, it can be classified as either intentional or unintentional, each having distinct implications.
Intentional technical debt arises when teams consciously prioritize speed over quality or maintainability, often to meet deadlines or quickly deliver a feature. While it can provide short-term benefits, it requires a plan for future refactoring.
Unintentional technical debt occurs without the team's awareness, often due to lack of experience, evolving requirements, or unforeseen complications in the system. This type of debt can be more challenging to identify and address because it accumulates gradually and silently impacts the system's health.
The table below summarizes some of the key differences between intentional and unintentional technical debt.
| Intentional technical debt | Unintentional technical debt | |
|---|---|---|
| How it occurs | Developers make deliberate compromises to meet immediate goals with awareness of the consequences. | Issues accumulate accidentally due to a lack of oversight or experience or because of evolving requirements. |
| Why it happens | To achieve quick wins or meet urgent deadlines, with plans to address the debt later. | Arises without planning, often due to unforeseen circumstances or lack of knowledge. |
| Team awareness | Known and typically planned for but can lead to issues if not addressed in time. | Often unnoticed until it causes significant problems, leading to unexpected costs. |
| Requirements for “paying back” the debt | Requires a clear plan for future refactoring and addressing the debt. | Requires regular code reviews, system design reviews, continuous learning, and monitoring to identify and address debt early. |
| Examples |
|
|
Types of technical debt
Besides categorizing debt as either intentional or unintentional, companies often employ additional labels to distinguish types of technical debt. While there are a variety of ways companies may classify technical debt, we will focus on the following four areas:
- Architectural debt
- Code-level debt
- Test debt
- Documentation debt
Each of these types of debt can arise either intentionally or unintentionally. In addition, each represents specific challenges and requires targeted strategies to mitigate its impact and ensure the system remains robust, maintainable, and scalable. By proactively addressing these forms of debt, teams can maintain high-quality software and avoid the pitfalls of accumulated technical debt.
In the sections that follow, we discuss common examples of each type of debt, the challenges they pose, and effective strategies to mitigate them.
Architectural debt
Architectural debt refers to the compromises made in designing or evolving a system's architecture. Over time, these decisions often accumulate, leading to increased system complexity, reduced performance, maintainability issues, and scaling difficulties.
Architectural debt incurs “interest” in the form of higher costs and risks over time. For example, a decision to delay implementing a modular design to save time may later require significant refactoring when new features need to be added or performance issues arise.
Architectural drift
Architectural drift refers to the gradual, unintentional deviation of a software system's architecture from its original design or intended blueprint over time. It occurs when discrepancies arise between the intended architecture and its actual implementation. These deviations introduce issues like inconsistent coding practices, redundant components, or tangled dependencies that were not part of the original architectural plan. While these changes do not directly violate the system's core design principles, they gradually misalign the system with its original intent. As undocumented decisions accumulate, the system becomes harder to maintain, and architecture plans or documentation no longer accurately reflect the state of the system.
For example, consider a retail application that was originally designed for simple online transactions. Over time, such an application may add features like inventory management, warehouse management, a retail store, a hybrid store, an internal application for store managers, etc. As new features are integrated, shortcuts may be taken to meet deadlines, leading to a system where components become tightly coupled and dependencies multiplied.
If adequate upfront planning does not take place, the architecture will likely stray from its original design. Dependencies between components and services may become complex, tightly coupled, and poorly documented, making it increasingly difficult to make changes, scale, and maintain the system.
Full-stack session recording
Learn more





How to address architectural drift
Architectural drift requires proactive strategies to ensure that the system remains aligned with its intended design:
- Use automated tools to detect drift: Automated tools like Multiplayer’s system dashboard monitor system changes and identify architectural drift in real time. The system dashboard automatically analyzes the system's structure, dependencies, and architecture, providing visual representations of the architecture and highlighting discrepancies between architecture diagrams and the live system. Integrating such tools into the development pipeline lets teams become aware of drift as soon as it occurs, allowing them to address any issues immediately.
- Strengthen architectural governance: Establish clear architectural guidelines and principles to guide developers and ensure consistent decision-making. Teams should document all architectural decisions, ensuring organizational transparency and alignment. This documentation is a reference for new team members and reduces the chances of unintentional drift caused by isolated decision-making. In addition, assign architectural ownership to maintain accountability for upholding the system's design integrity. Consider designating specific individuals or teams to oversee the system's design, ensuring that it aligns with established guidelines and long-term goals. These owners are accountable for maintaining architectural integrity, team coordination, and preventing unintentional design drift.
- Encourage cross-team collaboration: Collaboration among teams working on a system is important to avoid isolated, uncoordinated changes. Regular communication about architectural decisions helps prevent divergent paths that could lead to drift. Holding architecture-focused meetings allows teams to share insights, flag potential issues, and ensure alignment with the system's broader design goals.
Architectural erosion
Architectural erosion occurs when changes undermine the original architecture's foundational principles. New elements—such as tightly coupled modules, bypassed security protocols, or ignored performance constraints—weaken the system's structural integrity. These conflicts compromise the architecture, making the system fragile and prone to failure. Over time, unchecked architectural erosion leads to a system that becomes increasingly difficult to extend, maintain, or trust, significantly hindering future development.
As an example, consider a large-scale e-commerce platform built on a microservices architecture. Initially, each service is isolated and communicates via well-defined APIs to ensure modularity, scalability, and ease of maintenance, as shown below.


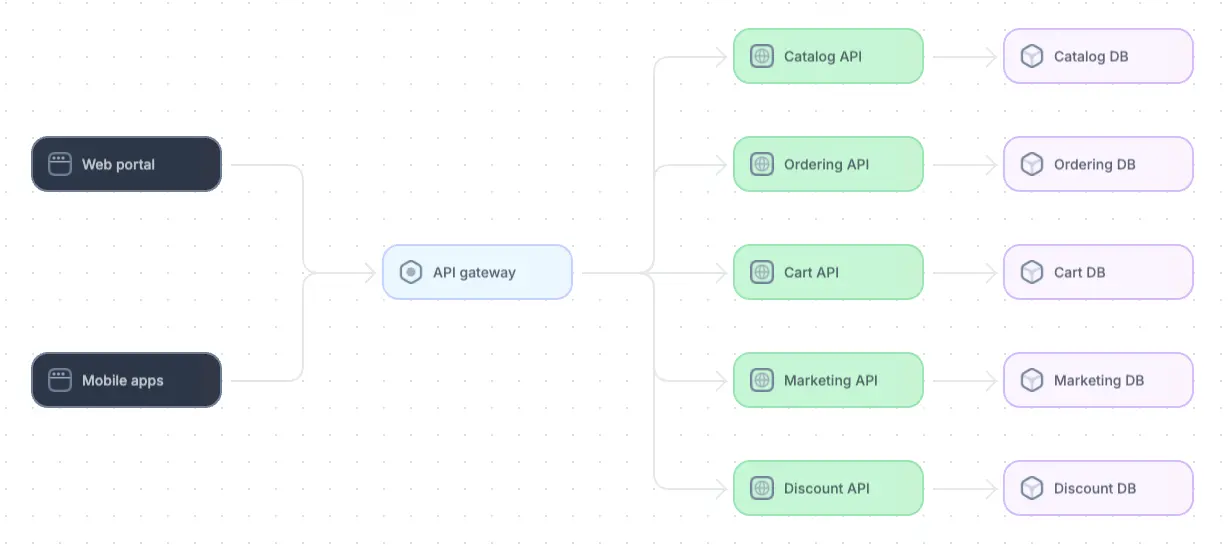
Example of an e-commerce microservice architecture diagram
However, over time, due to urgent feature requests and tight deadlines, developers begin bypassing these APIs and allowing services to interact directly with each other services' databases:


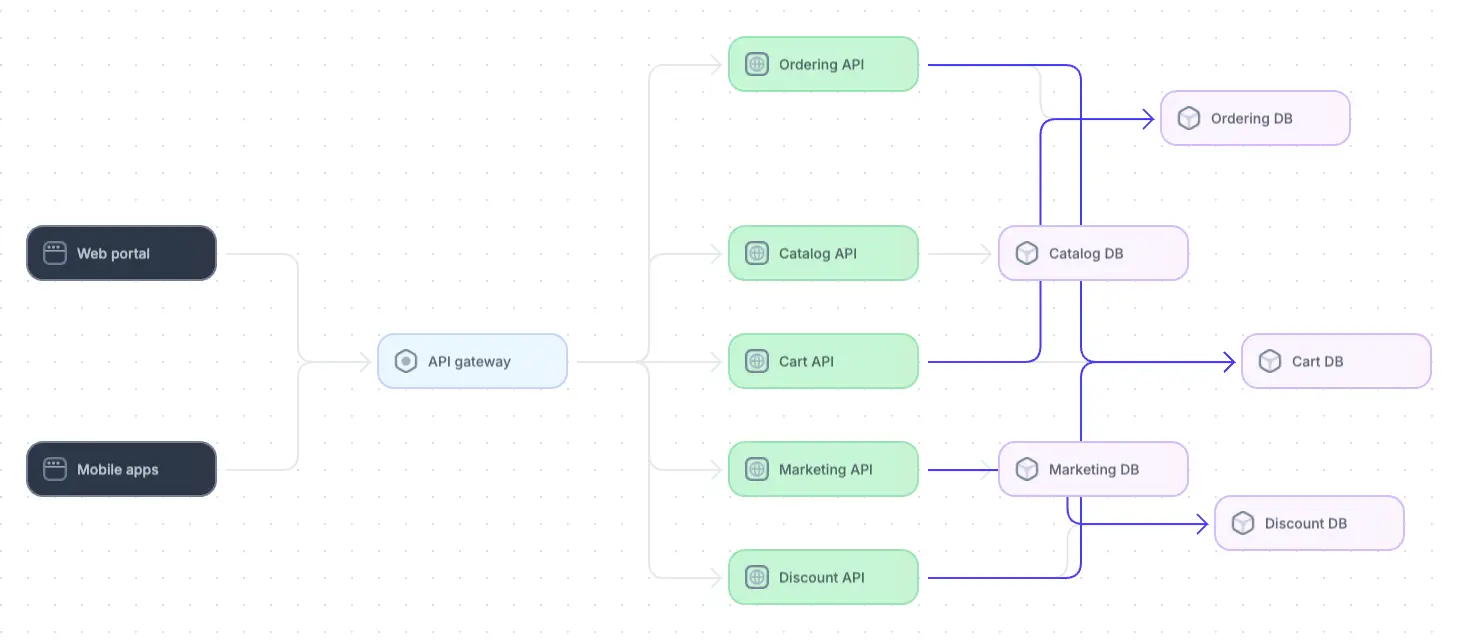
Example of an e-commerce microservice architectural erosion diagram
These shortcuts violate the fundamental principle of isolation and lead to tightly coupled services. As a result, changes in one service start impacting others, increasing the likelihood of system failures and bugs. The architecture, once clear and maintainable, becomes fragile and difficult to manage. This erosion of the original architectural design ultimately results in reduced system flexibility, increased maintenance costs, and a higher risk of failure as the system grows.
How to address architectural erosion
Implementing the following strategies can help address architectural erosion:
- Implement architectural observability: Start by conducting a detailed assessment of your current architecture. Take inventory of all system components to understand how far the system has deviated from the original design and identify areas where erosion has occurred. Automated tools like Multiplayer can simplify this process by providing a clear visualization of where erosion has taken place.
- Perform quick upfront system design reviews: Regular concise design reviews are essential to ensure that new features and changes align with existing architectural principles and best practices. These reviews prevent issues like technology lock-ins and feature creep, which can lead to erosion. By involving key stakeholders in the review process, you maintain the integrity of the system architecture and ensure that it adapts to future business needs without compromising its foundational design.
- Adopt modular architectures, domain-driven design (DDD), and behavior-driven design (BDD): Where erosion is particularly severe, transitioning to a modular architecture style (such as microservices) or implementing domain-driven design (DDD) can often help. Delineating boundaries between services or domains can reduce dependencies and improve scalability. This addresses the root causes of erosion by breaking down monolithic structures and promoting independent, well-defined components. In addition, integrating BDD into the development workflow helps ensure that the system's behavior aligns with user requirements and business goals. By focusing on defining clear behaviors through collaborative discussions with stakeholders, BDD facilitates the creation of well-defined, testable components. This minimizes the risk of architectural erosion and supports long-term architectural stability.
Interact with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
Code-level debt
Code-level debt refers to issues that arise within the codebase due to poor coding practices, lack of testing, inefficient algorithms, or suboptimal design patterns. Three common types of code-level debt are:
- Poor coding practices: Code that lacks structure, follows inconsistent naming conventions, or fails to adhere to design patterns results in unreadable and unmaintainable code. For example, excessive use of global variables or functions that perform too many tasks can make debugging and extending the code difficult.
- Lack of testing: Not having sufficient test coverage—such as unit tests, integration tests, or end-to-end tests—increases the risk of introducing bugs during future code changes. This is especially problematic in large codebases where changes can have unforeseen impacts.
- Inefficient algorithms: Using inefficient algorithms to handle core functions can cause slow performance, increased resource usage, and scalability issues. For instance, using an O(n2) sorting algorithm for large datasets could severely degrade performance.
How to address code-level debt
Consider the following approaches:
- Code reviews: Regular code reviews are essential for maintaining code quality. By involving multiple developers, code reviews help ensure that best practices are followed, code remains clean and consistent, and potential issues are caught early.
- Unit tests and test coverage: Unit tests validate individual components of the code and ensure that they work as intended. They are the most ubiquitous type of functional test because they are usually the easiest to write. Increasing unit test coverage helps catch bugs early, provides developers with confidence when making changes, and helps prevent code debt from accumulating.
- Code quality monitoring tools: Automated tools like linters, static code analyzers, and CI/CD pipelines can detect code smells, bugs, and vulnerabilities. These tools automatically scan the codebase for inefficiencies and violations of best practices and offer recommendations for improvement. Popular tools include Ruff for Python code linting and formatting, Credo for Elixir code's static analysis, and ESLint for JavaScript.
Test debt
Test debt arises from insufficient, outdated, or poorly written tests within a codebase. It includes gaps in test coverage, obsolete test cases, or the absence of automated tests. Test debt leads to an increased risk of defects and longer development cycles.
Examples of test debt:
- Insufficient test coverage: Important features or edge cases are not tested, leaving the system vulnerable to undetected bugs.
- Obsolete test cases: Tests that no longer reflect the current state of the application result in slow test execution, false positives, or missed failures.
- Manual testing overreliance: Relying heavily on manual testing is time-consuming and prone to human error.
How to address test debt
Consider the following approaches:
- Continuous integration / continuous delivery (CI/CD): Integrate automated tests into the CI/CD pipeline to ensure that new code changes do not break existing functionality. This helps maintain consistent test coverage and quickly identifies issues. Schedule regular test runs during each build or deployment to catch issues early and reduce the risk of undetected defects.
- Test-driven development (TDD): Adopt TDD practices by writing tests before implementing code. This ensures that tests cover the new functionality from the outset and helps prevent the accumulation of test debt. In addition, continuously refactor and improve tests alongside code changes to ensure that they remain relevant and effective.
- Testing as a shared responsibility: Encourage collaboration between development and testing teams. Make testing an integral part of the development process rather than a separate, isolated phase.
Documentation debt
Documentation debt refers to missing or outdated documentation of a system. This debt can hinder understanding, maintenance, effective communication, and onboarding. Here are some examples of documentation debt:
- Poor API documentation: APIs can lack detailed descriptions, usage examples, or clear explanations, making it difficult for developers to use them.
- Outdated system architecture documentation: Missing or outdated diagrams and descriptions of system architecture can complicate onboarding, troubleshooting, and system updates.
- Stale code comments: Outdated comments in the code lead to confusion and potential misuse of the codebase.
How to address documentation debt
Consider the following approaches:
- Keep documentation up to date: Establish processes for regularly updating documentation to reflect current code and architecture. Include documentation tasks in the development workflow to ensure that they are completed alongside code changes.
- Use effective tooling: Tools like Multiplayer notebooks can help teams craft interactive, executable documentation by including runnable code and API blocks alongside enriched text for ADRs, design decisions, and links to relevant assets. Notebooks can be created using natural language with AI or auto-generated from a full stack session recording to reduce manual documentation work.
- Establish documentation standards: Adopt and enforce documentation standards and formats across the codebase and system. This helps maintain consistency and improves readability. Provide clear guidelines and training for developers on how to write effective documentation, including what information should be included and how to format it.
Real-world technical debt example
The evolution of X (formerly Twitter) offers a compelling real-world example of how technical debt can accumulate and impact a platform's scalability and performance over time. As the platform rapidly grew, its early architectural choices struggled to keep pace with user demand.
In this section, we explore the technical debt timeline of X (formerly Twitter), highlighting how and why technical debt issues were introduced and providing best practices to avoid these types of issues in software projects.
One click. Full-stack visibility. All the data you need correlated in one session
RECORD A SESSION FOR FREE2006: Early growth and the Monorail
Twitter's original architecture, built on Ruby on Rails (Monorail), struggled to handle rapid user growth and high traffic loads. The reliance on a monolithic structure led to performance bottlenecks and outages, particularly during high-traffic events.
The limitations of Ruby on Rails in scaling for concurrent processes, combined with a monolithic codebase, made it difficult to introduce new features without compromising performance.
- Technical debt issues introduced: There was a poor separation of concerns, limited modularity, and a hard-to-scale monolithic architecture
- Root causes: Initial rapid growth outpaced the system's capacity, and there was a lack of foresight in planning for scaling from the beginning.
- Best practices to mitigate similar issues: Plan for scalability early with a focus on the architecture's future growth. Ensure clear separation of concerns with well-defined interfaces. Continue to revisit your system design over time. If your application is a growing monolith, regularly evaluate whether it is time to break components into services and transition to a modular architecture style, such as microservices, event-driven, etc.
2008: Introduction of Scala
Introducing Scala to address the performance issues solved some problems but created new challenges. While Scala offered better concurrency management, it created friction within engineering teams due to the split between Ruby and Scala developers. Inconsistent language and framework usage across teams caused fragmentation, making code maintenance and team collaboration more complex.
- Technical debt issues introduced: Inconsistent coding standards and complex code arose due to developer specialization in different languages.
- Root causes: There was a lack of alignment on long-term language strategy, creating technical silos within engineering teams.
- Best practices to mitigate similar issues: Establish and enforce company-wide coding standards. Promote cross-training among developers to prevent knowledge silos and encourage collaboration. Use automated tools to enforce consistency in style and code structure.
2009: Creation of the Science repo
As Twitter diversified its services, it created the Science repo to handle analytics and machine learning workloads. However, separating concerns into multiple repositories created an initial divide in the codebase, leading to technical constraints and inconsistent practices between teams working on different parts of the system. In addition, the introduction of multiple repos created complex interdependencies, making updates more challenging, particularly as the system grew.
- Technical debt issues introduced: The company experienced increased code duplication, divergent repo strategies, and harder-to-maintain build and testing pipelines.
- Root causes: A reactive decision to separate codebases without long-term architectural alignment or a dedicated maintenance strategy occurred.
- Best practices to mitigate similar issues: Consolidate common code into shared libraries or services to avoid duplication. Use a unified repository strategy with consistent build and testing pipelines. Automate testing and builds for consistency.
2010: Shift to service-oriented architecture (SOA)
After the 2010 World Cup revealed severe limitations in Twitter's ability to scale, the company shifted to a service-oriented architecture (SOA) using the Java Virtual Machine (JVM). This move improved scalability but introduced new challenges in the form of disparate services, varying engineering practices, and differing levels of scalability between services.
The rapid transition to SOA left some services under-documented and lacking in standardization, making it harder to maintain consistent deployment and monitoring across the architecture.
- Technical debt issues introduced: The issues included service sprawl, varied levels of reliability between services, lack of standardized service contracts, and missing services.
- Root causes: An urgent response to scalability challenges led to rushed architectural decisions, incomplete service documentation, and a lack of cohesive service management.
- Best practices to mitigate similar issues: Standardize service contracts (e.g., API specifications) and document all services comprehensively. Regularly review service reliability and implement service management tools. Limit unnecessary service creation by regularly auditing existing services.
2013: Monorepos and fragmentation
By 2013, Twitter's codebase was split between two massive monorepos: Science and Birdcage. Managing two separate repositories introduced significant challenges due to the complexities of interdependencies, lack of synchronization, and the challenge of maintaining consistent development environments across the codebases.
Keeping the repos up-to-date with each other became time-consuming and inefficient, further exacerbated by the lack of a dedicated team to maintain the codebases.
- Technical debt issues introduced: The most important concerns included dependency management difficulties, build and testing challenges, and fragmented development pipelines between code repositories.
- Root causes: The decision to split the codebase was based on technical limitations and divergent developer preferences instead of a unified architecture strategy.
- Best practices to mitigate similar issues: Centralize pipelines to ensure consistent build, testing, and deployment across projects. Regularly review dependencies for updates and compatibility. Use modern tools like Multiplayer to track drift in your system architecture and dependencies.
2013-2015: Engineering consolidation efforts
Twitter launched an initiative to consolidate its monorepos in 2013, aiming to reduce fragmentation and interdependencies. The creation of the Engineering Effectiveness group helped address some of these challenges, but the consolidation process was slow and involved many technical and organizational challenges.
While consolidating monorepos reduced certain inefficiencies, the process itself introduced new challenges, including the need to migrate legacy code and realign teams that had grown accustomed to separate workflows.
- Technical debt issues introduced: The company incurred architectural debt, and engineers disagreed on which Thrift compiler and other tooling to use.
- Root causes: There was a lack of consensus and standardization across engineering teams amid the growing complexity of architecture and tooling.
- Best practices to mitigate similar issues: Carefully choose a standardized set of tools for the organization and revisit these tools when making major refactors. Regularly review and update tooling policies, ensuring that they meet team needs and remain consistent across projects.
2014: Scaling success with the 2014 World Cup
Although Twitter successfully scaled to handle the immense tweet volumes of the 2014 World Cup, it continued to face challenges from fragmented engineering practices and inconsistent RPC implementations. In addition, disagreements over the usage of Thrift–particularly, which compiler to use and how to manage artifacts–continued.
This lack of standardized practices for critical technologies increased complexity and slowed down development, as teams had to manage and resolve discrepancies on an ongoing basis.
- Technical debt issues introduced: Lack of agreement on RPC standards, conflicting use of Thrift compilers, and increased complexity in managing service dependencies were key concerns.
- Root causes: There were divergent engineering practices across teams, a failure to reach a consensus on service communication protocols, and a lack of centralized architectural governance.
- Best practices to mitigate similar issues: Divergent engineering practices show the need for centralized governance. Create an architectural review board to enforce standardized practices and perform regular system design reviews. Promote collaboration and knowledge sharing across teams to align practices.
2022: Transition from Twitter to X and present-day evolution of X
The transition from Twitter to X brought significant organizational and technical changes. Massive layoffs reduced the number of engineers, leading to difficulties in maintaining the infrastructure. Frequent outages followed as the company struggled to keep the system running smoothly with fewer resources.
As X continues to evolve, the ongoing maintenance of its large-scale infrastructure presents new forms of technical debt. These include maintaining backward compatibility with legacy systems, managing internal tools like Pants for large-scale builds, and standardizing across a diverse range of services and technologies. Additionally, the strain from workforce reduction during the transition has exacerbated the challenges of scaling and reliability.
The role of AI
AI coding tools can help your team identify, manage, and reduce technical debt by automating or accelerating routine tasks like generating tests, writing documentation, or refactoring boilerplate code. More robust tools can even analyze large codebases and suggest different architectural patterns, improvements to development workflows, and development plans for new features.
However, AI tools’ effectiveness depends heavily on the quality and completeness of the context they receive. AI models often operate on static snapshots of code or partial system knowledge, and as a result, their suggestions can be too generic or miss important dependencies. In the worst cases, AI tools might suggest changes that compile and run locally but fail in a production environment or create subtle regressions. The more complex the system, the greater the risk that AI recommendations may miss critical nuances.
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREEBesides treating all AI-generated suggestions with an appropriate level of scrutiny, an effective way to mitigate these risks is to use tools that capture real-world system behavior and expose it in a way that AI can reason about. Tools like Multiplayer full stack session recordings can provide this context by capturing the complete execution path across the frontend, backend, and supporting infrastructure. Session recordings can then be used in a variety of ways. For example, teams can
- Replay execution paths to validate refactors
- Trace upstream and downstream dependencies affected by proposed changes
- Compare historical and current recordings to detect architectural drift, performance regressions, or unintended side effects
- Verify that documentation accurately reflects the system’s behavior
In addition, because Multiplayer exposes this data to AI tools via its MCP server, developers can generate AI recommendations informed by real execution context.


Debugging in the Cursor IDE using a full stack session recording
Last thoughts
This article has explored different types of technical debt, each of which poses unique challenges. If not managed, technical debt can severely slow development, increase costs, and degrade software quality. Here is a summary of the different types of technical debt and how to address them:
- Architectural debt erodes the system's structure, but practices like refactoring and adopting microservices can help prevent it.
- Code-level debt, such as poor practices and inadequate testing, can be addressed with code reviews and testing frameworks.
- Test and documentation debt can be tackled through continuous integration and maintaining up-to-date documentation using tools like Multiplayer.
The tech debt journey of X (formerly Twitter) illustrates how unchecked debt leads to inefficiencies and system instability, especially during major transitions. Organizations can mitigate these risks by prioritizing modular architecture, enforcing coding standards, conducting thorough testing, and performing regular documentation updates. Together, these practices ensure that the software remains scalable and resilient.