Guide
Platform Engineering: Tutorial & Examples
Table of Contents
Modern businesses require increasingly fast and reliable software delivery. As these business demands have grown, the limitations of traditional development and operational practices have become increasingly apparent. Platform engineering addresses these challenges by creating a standardized environment (or “platform”) that includes the tools necessary to build, test, and deploy applications. Unlike DevOps, which emphasizes collaboration between development and operations teams, platform engineering focuses on creating and maintaining stable, secure, and reliable platforms that abstract the complexity of managing infrastructure and allow developers to focus on writing code.
In an era where organizations manage complex, distributed systems and strive for rapid scalability, it is important to understand the distinction between platform engineering vs. DevOps while recognizing that they are complementary practices. One helpful way to distinguish platform engineering from DevOps is to consider each approach’s end users: DevOps examines the entire development process from end to end in an effort to improve collaboration between operations, QA, and development teams. Platform engineering serves developers specifically by providing them with a stable, simplified environment to deploy code, ideally without intervention from the operations team.
This article will demystify platform engineering by exploring its core principles, benefits, and challenges. We will explore what platform engineering is, its use cases, and why it is becoming indispensable in today's tech-driven world.
Summary of key platform engineering concepts
The table below summarizes five platform engineering concepts this article will explore in detail.
| Concept | Description |
|---|---|
| Understanding platform engineering | Platform engineering is designing and maintaining integrated, scalable infrastructure and tools that support the entire software development lifecycle. |
| Platform engineering use cases | Platform engineering helps organizations streamline their development processes and ensure rapid, reliable software delivery in environments like cloud computing and microservices architectures. It is also crucial for managing complex, large-scale systems where consistent and scalable infrastructure is needed. |
| Challenges in platform engineering | Platform engineering faces challenges such as managing the complexity of integrating diverse technologies and addressing team skill gaps Mitigating these challenges requires strategic planning, continuous learning, and adopting best practices to maintain a secure and efficient platform. |
| Platform engineering best practices | Best practices in platform engineering include automating infrastructure provisioning and management, implementing robust monitoring and logging, and fostering a culture of continuous improvement. |
| Spinnaker as a platform engineering case study | Spinnaker is an open-source platform, originally developed by Netflix and built on a microservices architecture. It is widely used to automate software deployment and delivery processes across multiple cloud environments. |
Understanding platform engineering
Platform engineering involves designing, building, and maintaining the infrastructure that supports the software development lifecycle. It focuses on creating a consistent and scalable platform for engineers to develop, test, and deploy applications efficiently. This approach abstracts the complexities of infrastructure management, enabling development teams to concentrate on writing code rather than worrying about the environment in which the code runs.
Platform engineering automates processes such as provisioning servers, configuring environments, managing dependencies, and ensuring system reliability. This automation reduces the risk of human error and accelerates the development pipeline.
Platform engineering use cases
In this section, we explore real-world use cases and how companies leverage platform engineering to solve complex challenges like cloud management, microservices orchestration, and data-intensive operations. The following examples illustrate the impact of platform engineering on software development lifecycles and operational efficiency.
Cloud-native application development and deployment
Use case overview
In a cloud-native environment, applications are built and deployed using cloud-based infrastructure and services. This setup requires a platform that can manage the complexities of cloud resources, automate deployments, and ensure scalability.
Platform engineering solution
- Infrastructure as Code (IaC): Platform engineering teams create reusable templates for infrastructure deployment using tools like Terraform or AWS CloudFormation. These templates ensure that all environments (development, staging, production) are consistently configured, reducing discrepancies and errors.
- Automated CI/CD pipelines: Continuous Integration and Continuous Deployment (CI/CD) pipelines are established to automate the build, test, and deployment processes. Tools like Jenkins, GitLab CI, or CircleCI are integrated into the platform, allowing developers to push code that is automatically tested and deployed to the cloud.
- Container orchestration: Kubernetes is often used to manage containerized applications, ensuring they are deployed, scaled, and worked consistently across different cloud environments. The platform abstracts the underlying cloud infrastructure, allowing developers to focus on application logic rather than deployment details.
- Environment provisioning: The infrastructure (servers, storage, networking, and software) required to run applications in different stages–such as development, testing, staging, and production–must be set up. Effective provisioning ensures consistency, scalability, and reliability across these environments, allowing developers to focus on building features while platform engineering teams manage the underlying resources.
Impact
- Scalability: Applications can automatically scale in response to traffic demands.
- Consistency: Uniform deployment environments reduce errors and improve reliability.
- Efficiency: Developers spend less time on infrastructure management and more on feature development.
Cloud-native architecture example


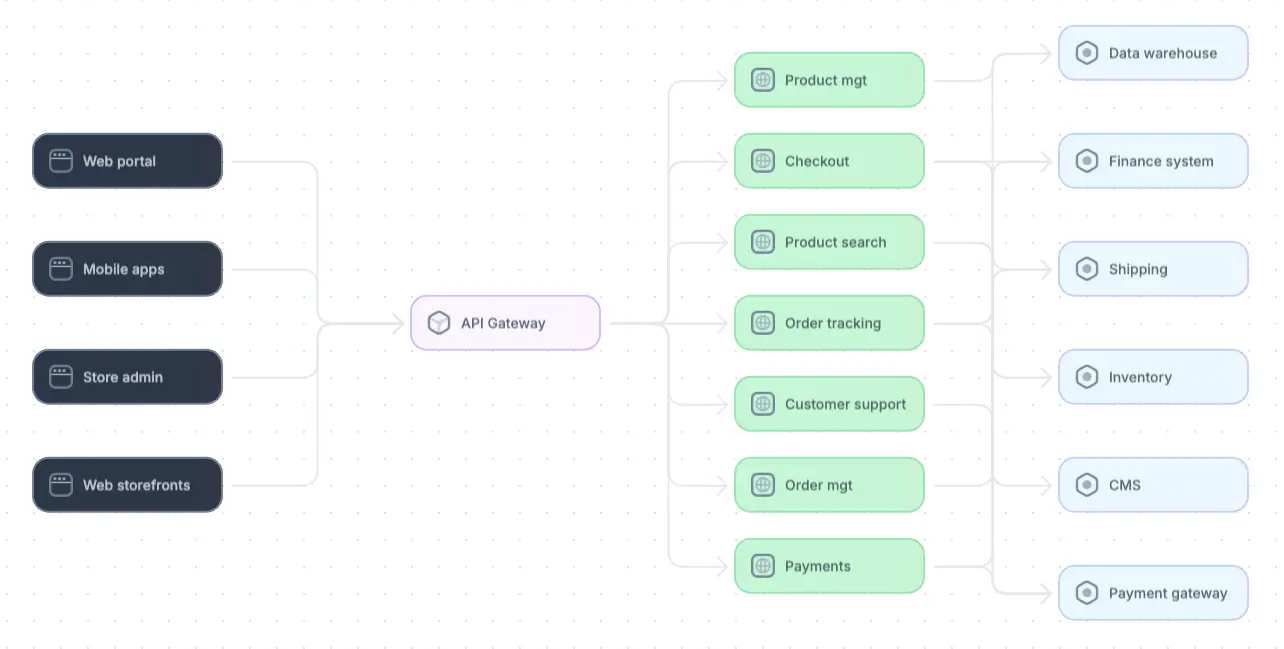
A logical overview of cloud-native architecture for an ecommerce application
Microservices architecture management
Use case overview
Organizations adopting a microservices architecture face challenges in managing multiple independent services that must communicate and operate together seamlessly. This requires a platform to handle service discovery, monitoring, and orchestration.
Platform engineering solution
- Service mesh implementation: A service mesh, like Istio or Linkerd, is integrated into the platform to manage service-to-service communication, security, and monitoring. This abstraction layer provides consistent policy enforcement and observability across all microservices.
- API gateway integration: The platform includes an API gateway (e.g., Kong, NGINX) to handle routing, load balancing, and authentication for incoming requests. This gateway simplifies the management of external APIs and internal microservices communication.
- Centralized monitoring and logging: The platform embeds tools like Prometheus for monitoring, Grafana for visualization, and the ELK (Elasticsearch, Logstash, Kibana) stack for logging. Together, they provide real-time insights into microservices performance.
Impact
- Reliability: Enhanced service communication and monitoring improve system reliability.
- Security: Consistent security policies across services reduce vulnerabilities.
- Developer agility: Developers can build and deploy microservices independently without worrying about the underlying infrastructure complexities.
Microservice architecture example


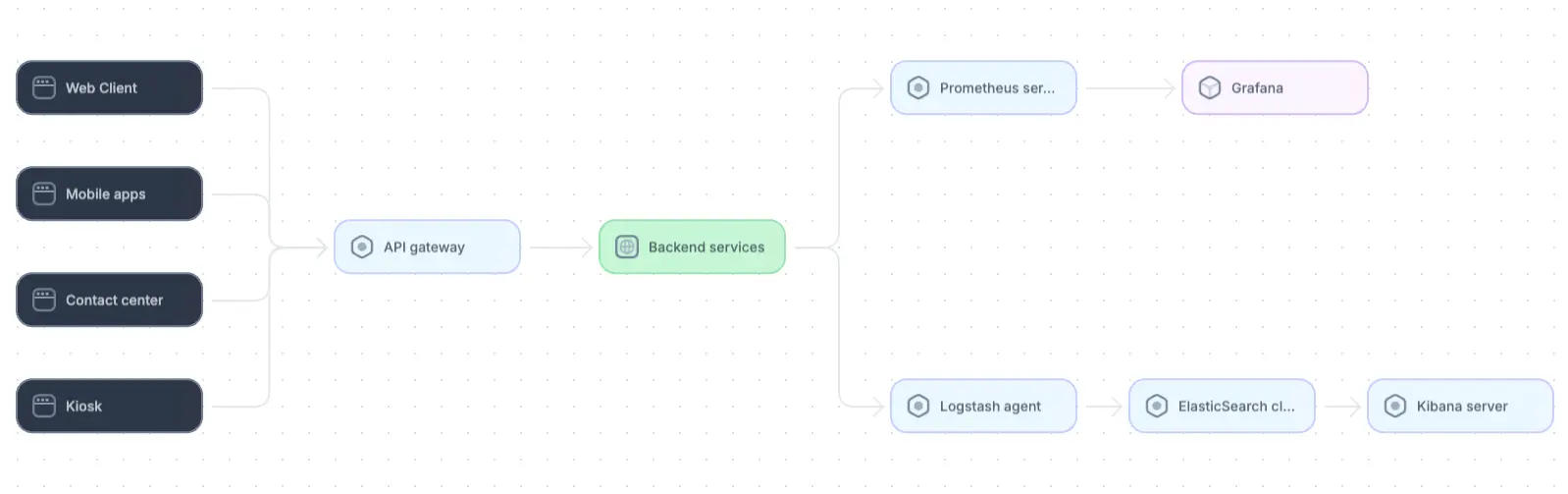
A logical overview of a microservices architecture using Prometheus, Grafana, and the ELK stack
Data-intensive application deployment
Use case overview
Efficient data management and processing are critical for applications that handle large volumes of data—such as analytics platforms, machine learning pipelines, or real-time data processing. This requires a platform that supports data ingestion, processing, storage, and analysis at scale.
Platform engineering solution
- Data pipeline automation: The platform includes tools like Apache Kafka for real-time data streaming, Apache Airflow for workflow orchestration, and Apache Spark for large-scale data processing. These tools automate data flow from ingestion to processing and storage.
- Scalable data storage solutions: The platform integrates scalable storage solutions like Amazon S3 for unstructured data and distributed databases like Apache Cassandra or Google BigQuery for structured data. This ensures that data can be stored and accessed efficiently, regardless of the volume.
- Machine learning operations (MLOps): For machine learning applications, the platform supports MLOps tools like Kubeflow or MLflow, which automate model training, validation, and deployment. This integration ensures that machine learning models can be developed and deployed at scale with consistent performance monitoring.
Full-stack session recording
Learn more





Impact
- Scalability: The platform handles large data volumes efficiently, enabling real-time processing and analytics.
- Efficiency: Automated data pipelines reduce manual intervention and errors.
- Innovation: Teams can focus on developing data-driven features without being bogged down by data infrastructure challenges.
Data-intensive architecture example


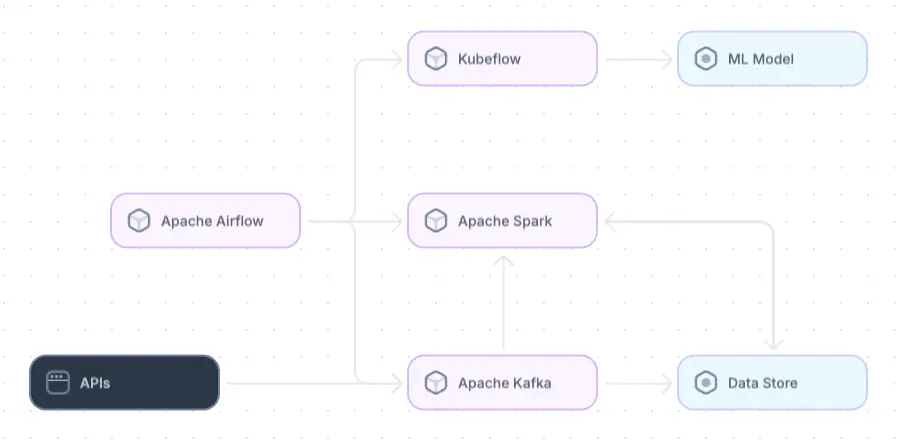
A logical overview of a data-intensive architecture
Platform engineering challenges
While platform engineering offers significant advantages in streamlining software development and operations, building robust and scalable platforms that support the complexities of modern software architectures is not trivial. Two significant barriers to engineering teams are the diversity of technologies required to build a platform and the expertise needed to wield these technologies effectively. These two challenges are explored below.
Integrating different tools
Modern platforms often rely on diverse technologies, including container orchestration systems like Kubernetes, CI/CD pipelines, service meshes, and monitoring tools. Ensuring that these components work together seamlessly requires deep expertise and meticulous planning.
For example, configuring a Kubernetes cluster to interact effectively with an API gateway and a service mesh can be intricate, requiring careful consideration of networking, security, and resource management. Even small misconfigurations can lead to significant issues, such as service outages or security vulnerabilities. In addition, maintaining consistency and reliability across all integrated components becomes increasingly challenging as the platform scales.
Cultivating a diversified skill set
Platform engineering requires software development, infrastructure management, automation, and security knowledge. Many platforms will include infrastructure as code (IaC) tools like Terraform or container orchestration via Kubernetes, both of which require considerable time and effort to master.
Building a team that combines the necessary expertise can be difficult for many organizations. The demand for skilled platform engineers often outpaces supply, leading to skill gaps that hinder a platform's successful implementation and operation. Moreover, even experienced teams face a steep learning curve when adopting new platform engineering tools and practices.
In addition, continuous learning is essential in this field as technologies constantly evolve. This need for ongoing education and adaptation can strain resources and delay project timelines.
Platform engineering best practices
Addressing the challenges above and building platforms that effectively support development, operations, and business goals requires thoughtful planning and investment of resources. In this section, we present six practices to help your team engineer platforms that are functional, secure, reliable, and adaptable to future needs.
Automate infrastructure management
One of the foundational principles of platform engineering is automation. Automating infrastructure management ensures consistency, reduces manual errors, and speeds up deployments. Tools like Terraform, Ansible, and Kubernetes enable teams to define infrastructure as code (IaC), allowing them to automate resource provisioning, configuration, and scaling.
Automation also extends to continuous integration and continuous deployment (CI/CD) pipelines, where automated testing, code integration, and deployment processes ensure that changes can be delivered quickly and reliably. By automating these workflows, teams can focus more on development and innovation rather than being bogged down by repetitive tasks.
Example: Creating an EC2 instance with Terraform
The example files below demonstrate how to create an AWS EC2 instance with Terraform.
variables.tf:
variable "aws_region" {
description = "The AWS region to deploy the resources in"
type = string
default = "us-east-1"
}
variable "instance_type" {
description = "The type of EC2 instance to deploy"
type = string
default = "t2.micro"
}
variable "ami_id" {
description = "The AMI ID to use for the EC2 instance"
type = string
default = "ami-0c55b159cbfafe1f0" # Example for Amazon Linux 2 in us-east-1
}
variable "key_name" {
description = "The name of the SSH key pair to use"
type = string
default = "my-key-pair"
}
variable "instance_name" {
description = "The name of the EC2 instance"
type = string
default = "my-ec2-instance"
}main.tf:
Interact with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
provider "aws" {
region = var.aws_region
}
resource "aws_instance" "example" {
ami = var.ami_id
instance_type = var.instance_type
key_name = var.key_name
tags = {
Name = var.instance_name
}
}terraform.tfvars: You can override the default values by creating a terraform.tfvars file:
aws_region = "us-west-2"
instance_type = "t3.micro"
ami_id = "ami-0abcdef1234567890"
key_name = "my-custom-key-pair"
instance_name = "production-ec2-instance"The code above allows you to deploy AWS EC2 instances in a way that is flexible and customizable. Each environment variable allows you to specify different configuration options, such as:
aws_region: The geographic region in which to deploy resources.instance_type: The type of EC2 instance to launch.ami_id: The Amazon Machine Image (AMI) ID for the instance.key_name: The SSH key pair name for accessing the instance remotely.instance_name: The name of the instance that will be displayed in the AWS console.
These variables can then be referenced in other parts of the Terraform configuration to avoid inconsistencies from hardcoding values.
Manage resources and costs
Effective resource management is vital in platform engineering, particularly in cloud environments where resources are dynamically allocated based on demand. While cloud computing's flexibility facilitates highly scalable platforms, it also introduces the challenge of balancing costs with performance and ensuring resource usage does not spiral out of control.
For example, over-provisioning resources to ensure high availability and performance can result in wasted capacity and inflated expenses. On the other hand, under-provisioning can lead to performance issues and service outages.
Addressing these challenges requires combining technical expertise, careful planning, and a commitment to continuous improvement. Consider the following approaches:
- Implement monitoring tools to track resource utilization
- Employ automation to adjust resources dynamically based on demand
- Regularly review and optimize infrastructure configurations, such as right-sizing instances and eliminating unused resources
A thoughtful combination of these approaches helps ensure the platform operates efficiently without overspending.
Ensure platform security
Security is critical in platform engineering, especially as platforms become more complex and interconnected. Securing a platform involves protecting the infrastructure and its data, applications, and communications. Ensuring security across the entire platform is a daunting task, requiring constant vigilance and the implementation of best practices at every layer.
Essential components of platform security include:
- Implementing strong access controls
- Encrypting data at rest and in transit
- Regularly updating and patching systems to protect against vulnerabilities, including those introduced by third-party libraries
- Securing APIs
- Complying with regulatory requirements like GDPR or HIPAA
- Conducting regular security audits and penetration testing to identify and mitigate potential threats.
- Incorporating tools like HashiCorp Vault for secret management and Istio for securing service-to-service communication within a service mesh.
By embedding security into the platform’s design and operation, teams can safeguard sensitive data and maintain compliance with regulatory standards.
Implement robust monitoring and logging
Robust monitoring tools like Prometheus and Grafana allow teams to closely monitor system metrics, such as CPU usage, memory consumption, and network latency. Proactive monitoring helps maintain the platform's health and performance by identifying potential issues before they escalate into critical problems.
In addition, logging provides a detailed record of system events and user interactions using tools like the ELK (Elasticsearch, Logstash, Kibana) stack or Fluentd. Centralized logging enables quick access to logs across the platform, simplifying troubleshooting and forensic analysis when issues arise.
Together, monitoring and logging provide the observability needed to maintain a reliable and responsive platform.
Extend visibility through full stack session recordings
Since the main goal of platform engineering is to provide developers with services that are reliable, performant, and easy to integrate with, it is particularly important for platform engineers to have comprehensive visibility into how platform services interact with the applications that rely on them under real-world usage. Traditional logs and metrics can capture what services report, but they cannot visualize and recreate how actual requests move through the production system.
An effective way to address these challenges is to add two key elements to your approach. First, instrument your services using observability frameworks like OpenTelemetry so that key events (user inputs, service calls, database queries, infrastructure signals, etc.) are captured. Next, add full stack session recordings to your observability approach using a tool like Multiplayer, which captures and automatically correlates frontend and backend data to provide developers with replayable sessions for debugging, feature validation, or contextual data they can feed to AI copilots to improve suggestions.


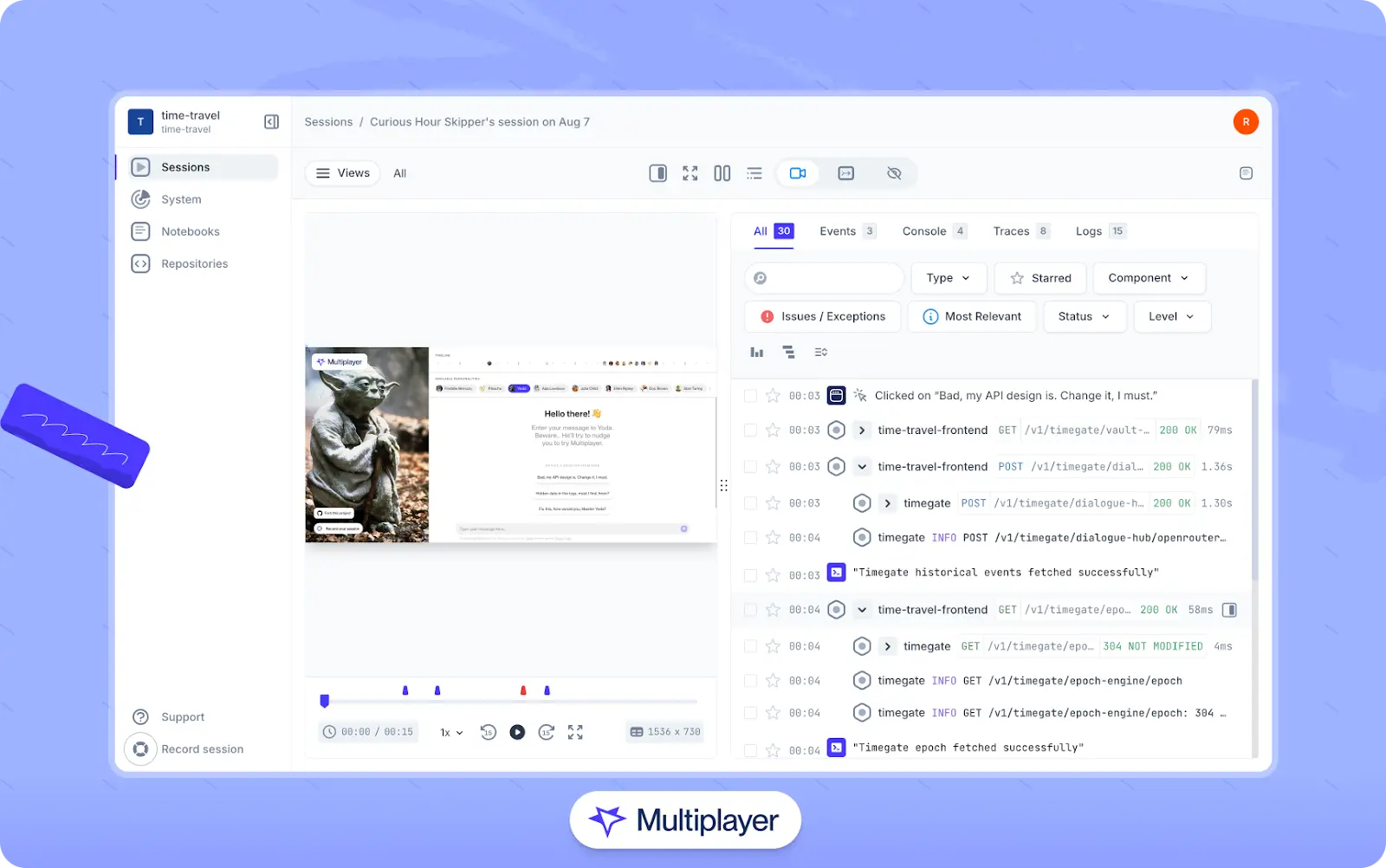
Multiplayer full stack session recordings
Once these tools are in place, platform engineers can capture events across the frontend, backend, and infrastructure layers and replay sessions to see:
- How platform services respond under real workloads.
- Latency spikes, errors, or unexpected behavior in the application.
- Integration issues, such as API misuse or incorrect feature flag handling.
Engineers can then use these insights to fix bugs, improve documentation or SDKs for developers, or optimize APIs, dependencies, or infrastructure.
Foster a culture of continuous improvement
Even if a platform effectively meets the needs of the development team, it is important to continue to revisit the platform and identify areas for improvement. Establish feedback loops for developers to report their experiences with the platform, and schedule regular performance reviews, retrospectives, and stakeholder meetings to gather insights on platform performance and challenges. Data from monitoring tools like Prometheus or Grafana can help quantify these observations and determine which areas should be prioritized based on metrics like resource utilization, latency, and error rates.
In addition, encourage experimentation by allowing teams to run small-scale pilots or proof-of-concepts, and use feature flags or isolated environments to validate changes safely without disrupting production. As with all changes and iterations, testing plays a key role in this process. If a robust suite of functional and nonfunctional tests is already included in integration and deployment processes, new versions of the platform can be deployed with greater confidence that they will not break existing functionality or create unexpected performance issues.
Spinnaker as a platform engineering case study
Now that we have explored platform engineering use cases, challenges, and best practices, let’s look at a real-world example. In this section, we will explore Spinnaker, a platform originally developed by Netflix to automate its deployment processes and meet the needs of its large-scale infrastructure.
Spinnaker overview
Spinnaker is an open-source, multi-cloud continuous delivery (CD) platform. It helps automate software deployment and delivery across multiple cloud environments. Designed for flexibility, scalability, and reliability, Spinnaker is now widely adopted beyond Netflix for managing software delivery pipelines.
Key Features:
- Multi-cloud support for seamless deployments across different environments.
- Continuous delivery pipelines to automate complex deployment workflows.
- Canary analysis and automated rollbacks to ensure safe deployments.
- High availability and resilience for handling large-scale microservices architectures.
Spinnaker architecture
Spinnaker is built on a microservices architecture with several key components:
- Orca (Orchestration Engine): Manages deployment pipelines and orchestrates their execution.
- Clouddriver (Cloud Integration): Provides integration with cloud providers like AWS, GCP, Azure, etc.
- Deck (UI): A web-based interface that allows users to manage pipelines and monitor deployments.
- Gate (API Gateway): Exposes Spinnaker’s capabilities through APIs for external integration.
- Igor (CI Integration): Integrates with continuous integration (CI) tools like Jenkins or Travis CI.
- Front50 (Storage): Stores pipeline configurations, metadata, and other persistent information.
- Echo (Notification and Triggers): Manages event-based triggers and notifications.
- Rosco (Image Baking): Automates the creation of machine images and Docker containers for deployment.
- Kayenta (Canary Analysis): Automates canary releases by comparing new versions' performance with the baseline production.
Each service is designed to handle a specific part of the continuous delivery process and ensure scalability, extensibility, and ease of use for DevOps teams.
Spinnaker pipelines and workflows
Spinnaker’s deployment pipelines are its core feature and enable complex automation workflows for continuous delivery. Spinnaker pipelines can include multiple stages, such as:
- Bake stage: Building machine or container images.
- Deploy stage: Deploying to target environments (e.g., AWS, Kubernetes).
- Verification: Running automated tests or canary analysis to validate releases.
- Manual judgment: Adding approval steps for sensitive deployments (e.g., production).
Pipelines are triggered based on events like Git commits, CI job completions, or manual interventions. This makes the continuous delivery process highly customizable.
Canary releases and automated rollbacks
Spinnaker supports canary releases through Kayenta, which compares performance metrics between a "canary" version (newly deployed) and the existing production version. The release is promoted if the canary’s metrics (such as error rates or latency) align with the stable version. If issues are detected, Spinnaker can automatically roll back the deployment to the previous stable version, minimizing risk.
Multi-cloud and Kubernetes integration
Spinnaker excels in multi-cloud environments, allowing teams to deploy to multiple cloud providers without changing workflows. Netflix, for example, uses Spinnaker to deploy its microservices across AWS and Kubernetes clusters, with Helm charts and native Kubernetes resource management supported out of the box.
Spinnaker at Netflix
Netflix’s streaming platform consists of hundreds of microservices that are frequently updated in production. Spinnaker enables Netflix to achieve:
- High-frequency deployments: Netflix can push updates to production multiple times daily across thousands of services.
- Safe, automated delivery: Netflix reduces the risk of faulty updates affecting users through canary analysis, automated rollbacks, and complex pipelines.
- Multi-cloud support: Spinnaker’s ability to manage services across multiple cloud providers allows Netflix to scale and evolve its cloud infrastructure quickly.
For Netflix, Spinnaker ensures that microservices are continuously and reliably deployed across its massive global infrastructure, helping it maintain high availability, performance, and resilience while rapidly delivering new features.
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREEConclusion
Platform engineering addresses the growing need for faster, more reliable software delivery. Whereas traditional DevOps practices focus on streamlining the entire software development lifecycle, platform engineering takes a developer-centric approach. It involves creating a dedicated platform that abstracts complexity, automates routine tasks, and provides developers with the tools and infrastructure they need to work more efficiently. In doing so, platform engineering empowers developers to innovate faster without worrying about complex operational details.