Guide
System Design Primer & Examples
Table of Contents
Software development is not just about writing lines of code. It is about building intricate systems that can handle the ever-growing demands of the digital world.
This article explores the fundamental principles of system design to help developers gain the necessary knowledge to design systems that are functional, resilient, efficient, and equipped to conquer the challenges of the modern web. It bridges the gap between crafting elegant code modules and designing robust, scalable systems.
Summary of key system design concepts
The table below summarizes important system design considerations covered in this article.
| Concept | Description |
|---|---|
| System design fundamentals | Scalability, reliability, maintainability, data consistency, security, networking, and performance are important considerations when designing distributed systems. |
| System design blueprint | An effective system design blueprint should cover purpose, scope, constraints, architectural design, data storage, scalability, and performance considerations. |
| Best practices | Best practices of system design include adequate upfront planning, clarifying the project’s technical direction, modularity, adequate documentation, achieving simplicity by using design patterns, and rigorous testing. |
System design fundamentals
System design is the foundation upon which robust and scalable applications are built. This goes beyond just building features—it involves meticulously defining the system’s architecture and the strategy to implement it. Proper system design ensures that the resulting software consistently meets both functional and non-functional requirements with the inherent flexibility to adapt and thrive as the application grows and demands evolve.
System designers craft software that serves as a sturdy and adaptable platform for an application by focusing on core principles like scalability, reliability, security, performance, and maintainability.
Scalability
One of the fundamental goals of system design is to ensure that an application can gracefully handle increasing demands, a concept known as scalability. There are two common techniques to achieve scalability in system design.
Horizontal and vertical scaling
In the horizontal scaling approach, the workload is distributed to multiple system nodes by adding more machines when needed. This allows the system to handle additional traffic or data without being limited by the capacity of a single machine. Vertical scaling, on the other hand, involves upgrading the existing machines with more powerful hardware (CPU, memory, etc.) to increase their processing power.
Depending on the use case, vertical scaling can be suitable for short-term bursts in demand but may not always be as effective as horizontal scaling in the long run. This is because hardware limitations place a hard limit on vertical scalability: Only a finite amount of CPU, memory, and storage can be added to a single machine. Beyond this point, further machine upgrades are either not possible or yield diminishing returns.


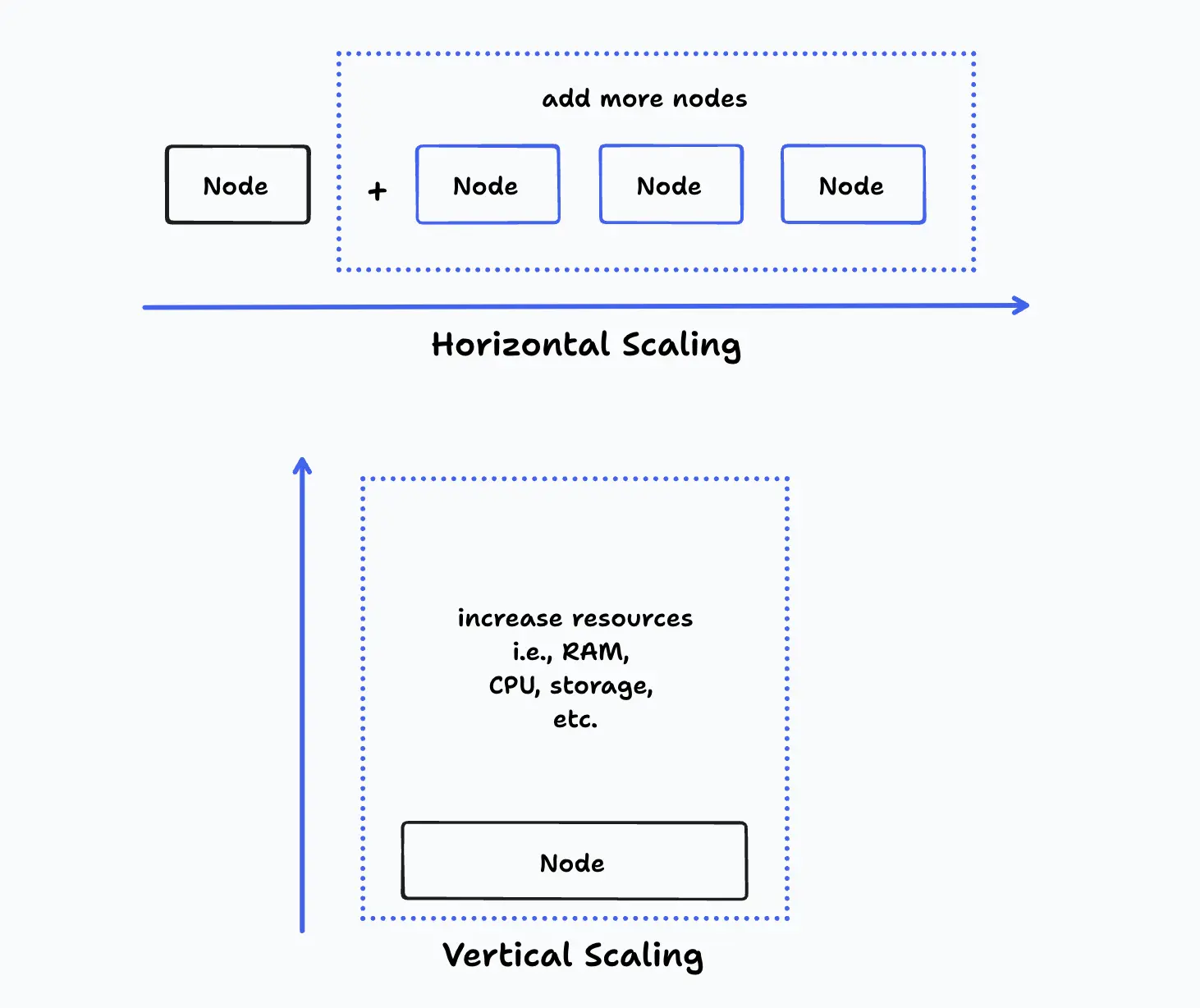
Horizontal and vertical scaling
Comparison of horizontal and vertical scaling
Both horizontal and vertical scaling have pros and cons.
| Area | Horizontal | Vertical |
|---|---|---|
| Cost | Generally more cost-effective in the long run for applications that expect significant user growth. | Saves costs upfront and can be more cost-effective if the system does not need to scale beyond the capacity of a single machine. |
| Complexity | More complex to manage | Relatively simple to manage |
| Performance | High performance on heavy load | Limited performance gain |
| Availability | Increased availability due to redundancy | Single point of failure |
While each use case is different, there are general principles to help you determine which scaling method to use.
Choose horizontal scaling if:
- You anticipate significant user growth in a short period.
- High availability and fault tolerance are critical.
Choose vertical scaling if:
- You have a relatively stable user base.
- Simplicity in management is preferred.
- Faster implementation is crucial.
When scaling vertically, it is important to determine the right metric to use, which helps with calculating the allocation targets. Resource utilization and performance metrics are the primary indicators for identifying vertical scaling opportunities. CPU, RAM, and storage usage efficiency assessments can also provide valuable insights; combine these with measurements of speed, response time, and other relevant performance metrics to create a comprehensive picture of the situation. In addition, comparing the costs associated with vertical scaling against anticipated growth and the benefits gained helps determine if this approach will remain cost-effective in the long term.
Load balancing
Load balancing distributes incoming user requests across a pool of multiple servers so that no single server becomes overloaded. This results in faster response times and a more robust system while enhancing application availability. In addition, if one server within the pool encounters an issue, the load balancer seamlessly redirects traffic to healthy servers.


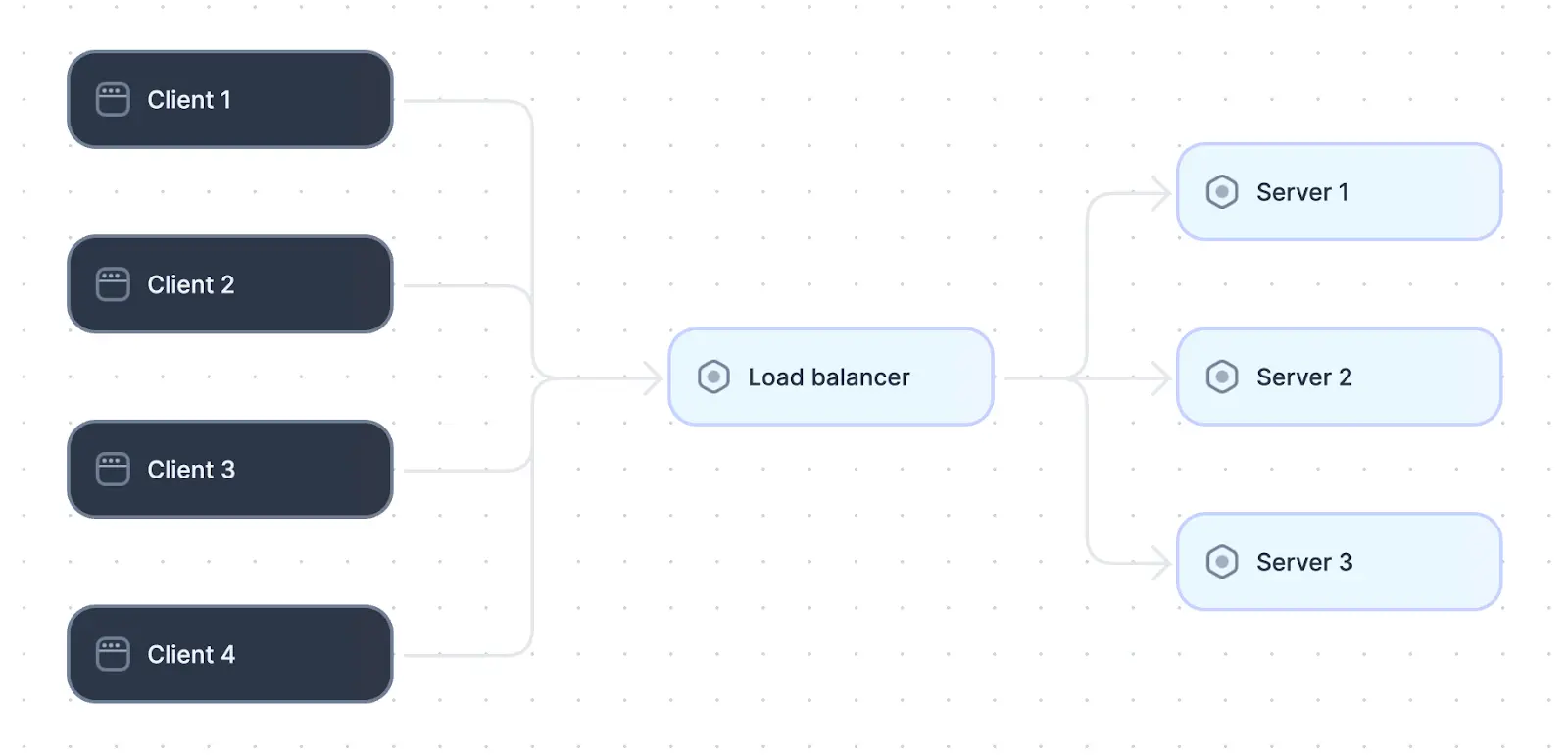
Load balancers distribute load across multiple servers
Consider factors like traffic volume, desired performance, and budget when selecting a hardware-, software-, or DNS-based load balancer. Analyze your system’s specific needs to choose the most appropriate load balancing algorithm for traffic distribution. Continuously monitor the health and performance of your servers and make sure that the load balancer is correctly identifying and removing unhealthy servers from the pool to maintain optimal service levels.
Caching
Caching is a technique that boosts application performance and scalability by creating a temporary copy of frequently accessed data in a high-speed location that is closer to where it is needed. This significantly reduces the time it takes to retrieve data.

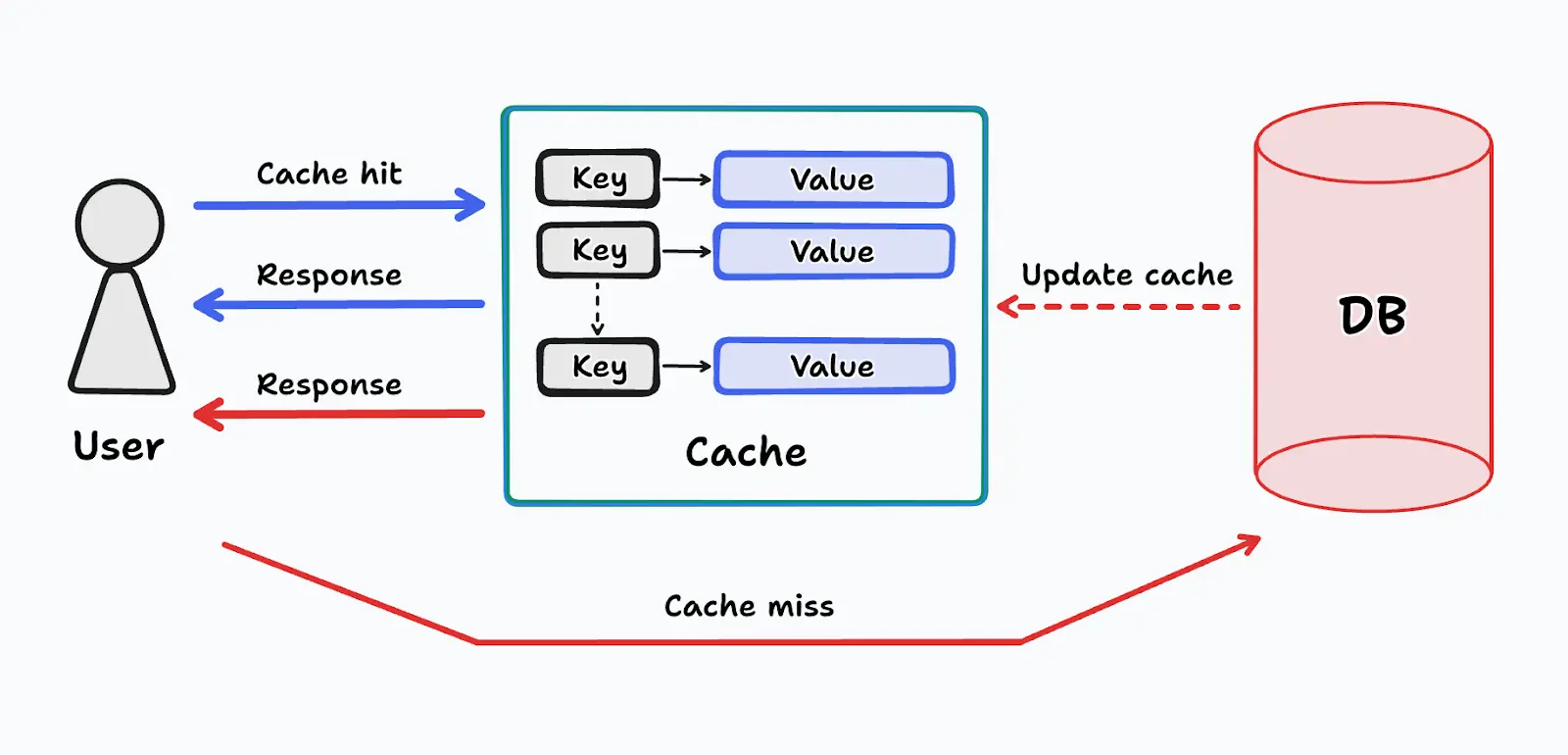
Caching solutions serve frequently accessed data to end users
Full-stack session recording
Learn more





Caching offers several benefits. First, it dramatically reduces latency by delivering data instantaneously from the cache, making the application feel faster and more responsive. Second, having the cache strategically handle read requests reduces the load on the primary data source (databases or servers), which frees up resources for more critical tasks and leads to improved overall system stability.
Caching strategies
Caching involves implementing effective strategies to optimize system performance without overburdening resources, including the following:
- Determining which data elements are accessed frequently and are critical for system performance
- Implementing mechanisms to invalidate cache entries when the underlying data changes so that stale data is not served to users
- Setting expiration policies based on the volatility of data
- Segmenting the cache based on data types or access patterns
- Adopting lazy loading techniques to populate the cache only when data is requested
- Implementing cache invalidation policies to remove less frequently accessed or older cache entries when the cache reaches its capacity limit
Reliability and availability
Reliability extends beyond simply avoiding errors—it’s about the system’s ability to handle errors gracefully. A reliable system can identify and respond to errors effectively, preventing crashes and consistently delivering the expected results without errors or unexpected behavior.
Availability focuses on ensuring that the system is consistently available for users with minimal downtime. System designers often incorporate backup systems or redundant components to achieve high availability. This redundancy acts as a safety net: If a primary component fails, a backup system can take over, ensuring that the system remains operational and minimizes downtime for users.


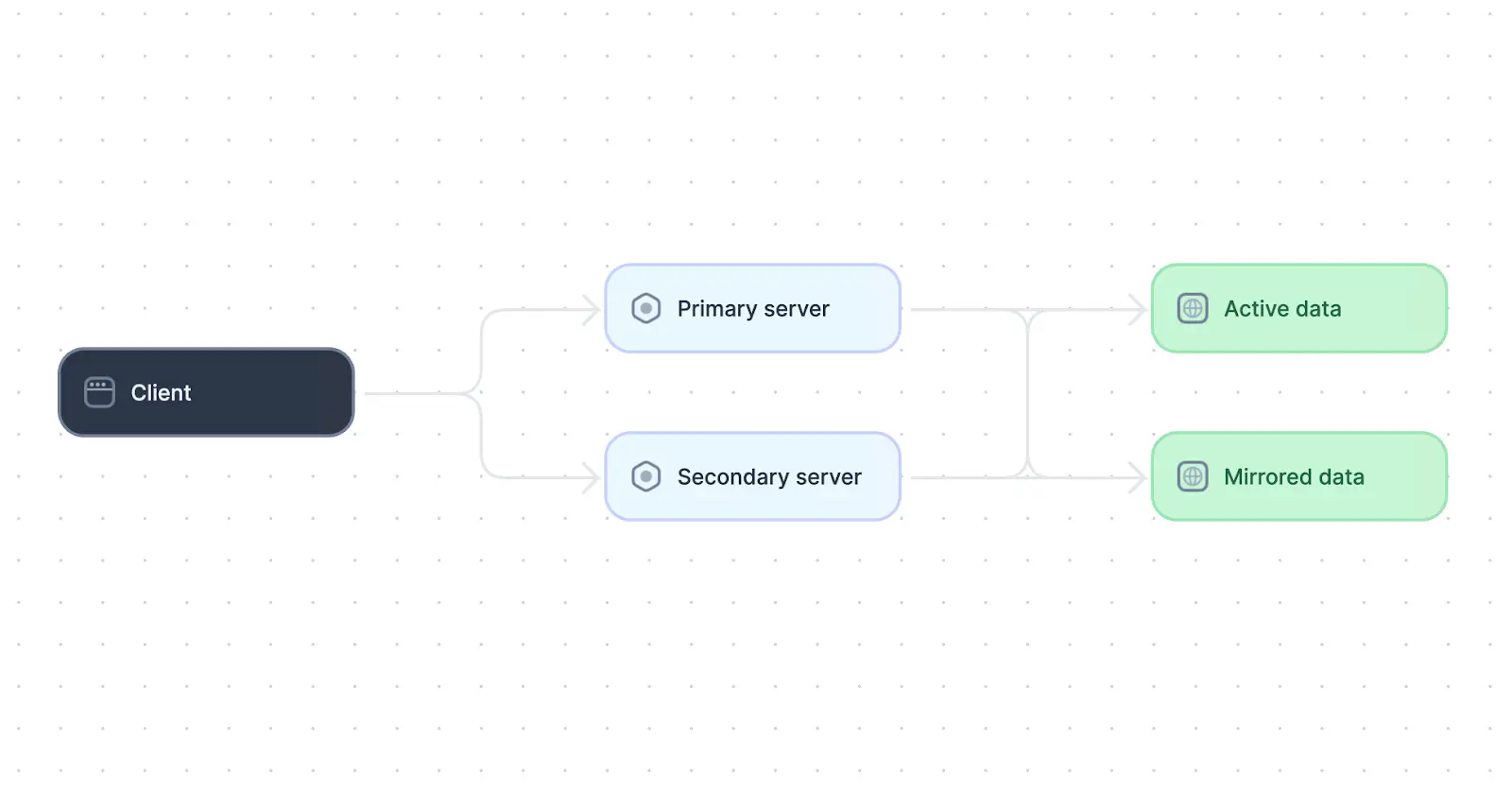
Example system with high availability
The system above achieves high availability through the use of a redundant server and database. In such a system, database replication techniques can be employed to maintain data consistency across data stores, and automated health checks and failover mechanisms can be implemented to switch to the secondary server if the primary server fails.
Maintainability
Maintainability is the ability to modify, update, and fix a system effectively over its lifecycle. A well-maintained system makes it easier to adapt to new requirements, debug issues, and ultimately, keep development costs under control.
Maintainable code is clean, well-organized, and adheres to a clear separation of concerns. This means the code is broken down into well-defined modules, each with a specific responsibility. Modules are well-defined, independent units with clear and documented interfaces that specify how modules interact with each other.
Data consistency
Distributed systems introduce the challenge of maintaining consistency across multiple data copies. In such cases, different data consistency models dictate how updates are handled:
- Strong consistency ensures that all data replicas reflect the latest update immediately. This guarantees data integrity but can impact performance due to the overhead of synchronizing all replicas.
- Eventual consistency allows for temporary inconsistencies as updates are eventually propagated across all replicas. This offers better performance but may result in users occasionally seeing slightly outdated data.
- Causal consistency ensures that updates are applied in the same order across all replicas, but does not guarantee immediate consistency. It offers a balance between performance and consistency requirements.
The choice of consistency model varies based on application requirements. For applications where it is critical to always read the most up-to-date data–such as financial or stock trading systems–strong consistency is necessary. However, for highly available and performant systems where temporary inconsistencies are acceptable–such as DNS systems and caching solutions–architects may choose an eventual consistency model.
Security
An application’s security layer consists of measures designed to protect systems from unauthorized access, data breaches, and other malicious activities. It involves implementing security practices at different levels of the application architecture to ensure data integrity, confidentiality, and availability. Some common security practices include:
- Authentication: the process of verifying a user’s claimed identity through mechanisms like passwords, tokens, or multi-factor authentication.
- Authorization: even after a user’s identity is verified, it is crucial to control what actions they can perform within the system. Authorization controls which resources and functionalities an authenticated user can access based on their assigned permissions.
- Data security: the practice of protecting sensitive data both while stored within the system (at rest) and during transmission over networks (in transit). Data encryption plays a key role in this process by scrambling data using algorithms and keys to make it unreadable to unauthorized parties even if intercepted.
Networks and communication
Robust network infrastructure and well-defined protocols ensure efficient data exchange and system functionality. Network protocols act as the common language for data exchange between system components. They define the rules and formats for data transmission, ensuring efficient and reliable communication. Choosing the appropriate network protocol depends on the system's specific needs. Factors like real-time vs. asynchronous communication, data sensitivity, and the desired level of performance all influence the selection process.
Performance and efficiency
Ensuring a system’s performance and efficiency depends on several key strategies. For a faster user experience, content delivery networks (CDNs) can distribute static content like images and scripts geographically, minimizing load times. Optimizing data retrieval involves reducing the number of database calls through caching and proper indexing, allowing the system to locate information quickly.
Efficiency is also achieved by minimizing resource consumption. Code and system logic analysis helps identify areas where unnecessary computations can be eliminated, and monitoring resource utilization allows for the proactive identification of bottlenecks. For developers writing code, avoiding redundant operations and excessive processing loops streamlines execution and improves application response times.
System design blueprint
There is no one-size-fits-all approach to designing distributed systems. System design is an expansive topic with many core principles, and each use case requires a different set of approaches depending on the problems the system is attempting to address. For example, designing and scaling a monolithic application system is different from designing a system with a microservices architecture. The sections below describe some of the core components of system design and provide real-world examples.
Interact with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
System overview
A system overview provides a high-level introduction to the system, outlining its core aspects. These aspects include the following:
- Purpose clearly defines the system’s intended function and the problem it aims to solve. What value will the system deliver to users or the organization? Here, a concise yet informative statement outlining the system’s primary goal is essential.
- Scope defines the boundaries of the system, specifying what functionalities it will encompass and what will be excluded. This helps manage expectations and avoid feature creep during development. A well-defined scope ensures development efforts are focused on delivering core functionalities within a reasonable timeframe.
- Constraints encompass any limitations or restrictions that might influence the system’s design. These may include resource limitations, technical dependencies, and regulatory requirements.
This overview should be stored with other system architecture documentation and can also serve as a starting point for an architecture decision record (ADR) in the later stages of the system’s development.
Architectural design
The architectural design portion of the blueprint provides a clear, high-level architectural diagram of the entire system. It depicts all the major components of the system, including services and their interactions, using system architecture diagrams, sequence diagrams, network diagrams, flowcharts, or other diagrams where needed.
When crafting diagrams, it is important to strike a balance between simplicity and completeness. Excessive detail can overwhelm the diagram’s audience, hindering their ability to grasp the system’s core functionality, while omitting essential details can lead to misinterpretations of the system’s behavior.
Some common features of system architecture diagrams are listed below.
System components
These represent the fundamental building blocks of the system, such as databases, servers, clients, user interfaces, and external services. Each component is visually represented using a standard notation for easy comprehension.
Interactions and relationships
Arrows or lines illustrate how these components interact with each other to highlight data flow, service calls, and message exchanges among various parts of the system.
Communication protocols
The diagram might specify how components communicate (e.g., using APIs or message queues), providing insight into the underlying mechanisms facilitating interaction.


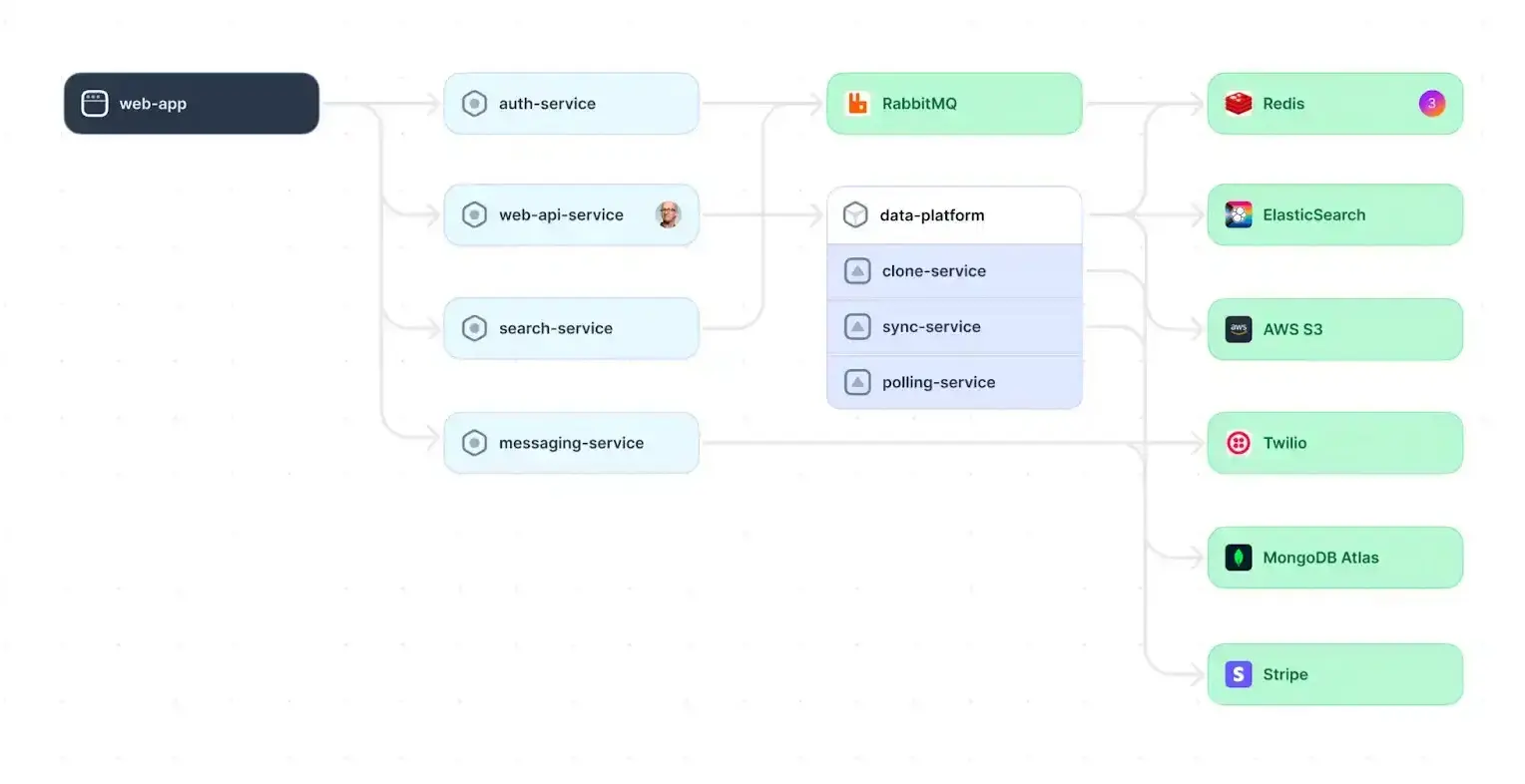
Example of a system architecture diagram
Along with the above, an architectural diagram might also contain layers, external systems, and annotation/descriptions of system components or connections.
Data and storage
Choosing the right database can be challenging. Here are some factors to consider when determining which type of database best suits your application:
- Data structure—structured, semi-structured, or unstructured—plays a critical role in database selection. Structured data—such as user records or customer information—thrives in relational databases. Unstructured data—such as images and videos—is better suited to non-relational (NoSQL) databases with efficient storage and retrieval features.
- Scalability requirements must be considered if your application anticipates significant growth. NoSQL databases are generally more adept at handling growth spikes since it is possible to seamlessly scale them horizontally by adding more servers.
- Performance needs include desired response times and system throughput. Different databases offer varying levels of performance. If the application demands real-time data processing or handles high transaction volumes, consider in-memory databases that store data in RAM for fast access.
- Specific application requirements may encompass unique functionalities or access patterns of your application, which can influence database selection as well. For example, if the system requires modeling relationships within social networks or recommendation systems, graph databases are an excellent choice. However, if it needs complex queries or the joining of multiple database tables, then relational databases with strong query languages will be advantageous.
Data model
Designing a robust data model involves identifying entities, their attributes, and the relationships among them. Choose appropriate database structures—such as relational, non-relational, or graph—based on the nature of the data and the requirements of the application. In addition, do not forget to consider factors like scalability, flexibility, and performance when selecting a data model.
When designing data models for distributed systems, you may also have to consider the following key challenges, depending on the nature of your system:
- Sharding refers to breaking down large datasets into smaller, more manageable partitions (shards) that are distributed across multiple nodes. Implementing sharding requires careful consideration of data distribution, shard keys, and balancing data across shards.
- Replication of data across multiple nodes ensures fault tolerance, high availability, and load distribution. Implement strategies for data consistency, conflict resolution, and synchronization among replicas.
Performance considerations
Attaining high performance involves carefully analyzing various factors that can impact the speed, efficiency, and scalability of the system. Here are some examples:
- Data indexing and optimization: Implement efficient indexing strategies to expedite data retrieval operations and improve query performance. Regularly optimize database schemas, indexing structures, and query execution plans to minimize overhead and enhance database performance.
- Fault tolerance and resilience: Design the system with fault tolerance mechanisms to withstand failures and ensure continuous operation. Implement redundancy, failover strategies, and data replication to mitigate the impact of hardware failures and network disruptions.
- Latency optimization: Minimize response times and latency to enhance the user experience. Optimize data retrieval, processing, and network communication to reduce the time taken for operations. Utilize caching mechanisms, asynchronous processing, and content delivery networks to mitigate latency issues.
- Concurrency management: Handle concurrent requests and data access efficiently to prevent contention and bottlenecks. Utilize concurrency control mechanisms such as locking, multi-threading, and distributed transactions to ensure data integrity and optimize throughput.
One click. Full-stack visibility. All the data you need correlated in one session
RECORD A SESSION FOR FREESystem design best practices
Next, let’s delve into best practices that promote code clarity, effective documentation, and a balance between upfront planning and ongoing flexibility within distributed systems.
Keep things simple
Prioritize clarity, modularity, and well-established design patterns to create robust and maintainable systems. By clearly communicating the technical direction with well-defined goals, the focus remains on core functionality, avoiding unnecessary complexity or premature optimizations. This facilitates collaboration among developers, reduces the risk of misunderstandings, and ensures that all stakeholders are aligned with the system’s objectives.
A modular approach to system design also enhances simplicity. The system should be broken down into well-defined, independent modules with clear responsibilities, which fosters maintainability in the long run. Individual modules become easier to understand, test, and modify without impacting the entire system. Modularity also promotes code reuse, reducing development time and effort.
Another aspect of simplification is using well-established design patterns. These patterns are proven solutions to recurring design problems, offering a foundation for building robust and efficient systems. By utilizing existing patterns, developers can avoid reinventing the wheel and focus on the unique aspects of the system. This not only saves development time but also promotes code consistency and maintainability.
Create proper documentation
Clear documentation facilitates troubleshooting, debugging, and future modifications by providing a readily available reference point. It serves as a bridge among developers, future maintainers, and anyone else who needs to grasp the system’s intricacies. Focus on providing clear and essential information, and avoid unnecessary jargon or overly verbose explanations. Strive for accuracy by ensuring that the documentation reflects the system’s actual functionality. Also, regular updates are necessary to reflect changes in functionalities, architecture, or configurations.
Comprehensive documentation allows new developers or team members to grasp the system quickly, minimizing onboarding time and effort. Utilize diagrams and flowcharts to illustrate complex concepts, system workflows, and data flow. In addition, moving beyond static text can make the docs better reflect the current state of your system and therefore more useful in practice.
For example, tools like Multiplayer notebooks combine enriched text for narrative explanations with executable code and API calls to demonstrate how components interact, verify interface contracts, and record artifacts like architectural decision records, system design decisions, and technical debt directly alongside other forms of documentation. Rather than relying on docs scattered across multiple tools (wikis, API clients, code repositories, diagramming tools, etc.), teams can view comprehensive documentation in a centralized location and execute blocks to validate assumptions, reproduce scenarios, and explore live data directly within the documentation itself.
Plan ahead
Striking a balance between upfront planning and ongoing adaptability is essential in modern system design. Investing time in upfront planning lays a solid foundation for the system’s architecture and design. Understanding user needs, functionalities, and success metrics is crucial for designing a system that delivers value. Selecting an architectural approach that aligns with the system’s purpose and scales effectively while proactively considering potential technical limitations, security risks, and scalability bottlenecks allows for early mitigation strategies.
However, it is equally important to avoid getting bogged down in excessive pre-design. Modern agile development methodologies emphasize flexibility and adaptability to changing requirements, which can be hindered by overly rigid planning. User needs and business landscapes can shift over time, so being overly prescriptive in the initial design limits the system’s ability to adapt.
Leverage existing solutions
Leveraging existing cloud services, libraries, and frameworks can significantly benefit the development process.
Cloud services
Cloud computing offers a vast array of services, from storage and databases to machine learning and AI capabilities. By utilizing readily available cloud services such as AWS, GCP, Azure, Oracle, etc., developers can offload functionalities and focus on building the core aspects of their system.
That being said, the cost of utilizing cloud services should also be taken into account. It is important to project costs carefully and only proceed with a given solution if it is feasible. In some cases, custom or on-premise solutions are more suitable.
Libraries
Code libraries can address common programming tasks like data manipulation, network communication, or user interface development. Utilizing well-supported and well-documented libraries saves development time and ensures the implementation of properly tested capabilities.
For example, when building a complex single-page application (SPA), instead of writing custom logic for client-side data updates from scratch, consider leveraging a library like Redux for state management. You can also utilize pre-built Redux middleware libraries that integrate seamlessly with Redux’s core functionality, streamlining data handling and optimizing performance. This approach saves development time and ensures well-tested, high-performance solutions for common functions within the SPA.
Frameworks
Frameworks are more comprehensive than libraries, offering predefined structures and sets of tools for building specific types of applications. They provide a foundation upon which developers can build custom functionalities.
Django and Ruby on Rails are two examples of frameworks that provide the functionality to quickly prototype and build applications.
Focus on maintainability
Maintainability is a strategic investment that delivers long-term benefits for the system, saving time and money in the long run. Here are a few features of maintainable applications:
- Clean and well-documented code: Use clear and consistent naming conventions, proper indentation, and adequate comments, and avoid unnecessary complexity.
- Organized codebase: A well-organized project structure and codebase enhance understanding of the system’s design, functionalities, and decision-making processes.
- Version control system: Use version control systems such as Git or SVN to track code changes and histories. This also enables quick rollback of changes when necessary.
- Issue trackers: Use bug trackers to document bug fixes. This helps to quickly trace changes based on past issues, find relevant sections of code, and resolve new issues before they become unmanageable.
- Periodically reevaluate design decisions: Continue to iterate on system design. Reduce technical debt by assessing existing design decisions regularly and optimizing them whenever possible.
Conduct rigorous testing
Evaluate the system to identify and rectify any bugs or errors by performing rigorous testing before code is shipped to production. There are numerous types of software tests, and a comprehensive testing strategy should combine them strategically throughout the development cycle to verify both functional and non-functional requirements.
- Unit tests focus on the smallest testable pieces of code, typically individual functions or classes. The goal is to verify that each unit behaves as expected under various input conditions.
- Integration tests verify how different units interact and work together as a whole. This involves testing the interfaces between modules and ensuring that data flows smoothly across the system.
- Performance tests assess the system’s behavior under load. This approach means simulating real-world usage patterns and monitoring factors like response times, resource utilization, and scalability.
Comprehensive testing leads to a more polished and reliable system, minimizing the likelihood of errors or unexpected behavior in production.
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREEExplore user flows
Even when teams follow best practices around architecture planning, tooling, maintainability, documentation, and testing, unexpected issues inevitably arise in the production system. When this happens, developers must have sufficient visibility to understand why the system failed and explore which user actions and system behaviors led to the problem.
Start by integrating monitoring and observability practices into your workflow. This can be achieved using a combination of tools, such as distributed tracing frameworks, metrics collection tools, and centralized logging platforms, to capture the state and behavior of each service in real time. You do not need to instrument your entire application, but instrumenting critical paths with these tools allows developers to see how requests propagate through the system, identify latency or error hotspots, and correlate failures across services.
To complement this approach and correlate backend behavior with user actions on the front end, consider utilizing session recording tools to capture end-to-end session data. For example, tools like Multiplayer’s full stack session recordings capture a wide array of data correlated per session, such as:
- User clicks + inputs
- Page navigations + loads
- Session metadata (browser/OS information, device type, screen size, cookies, etc.)
- DOM events
- Console messages (message + stack trace)
- Network requests
- Backend errors
- Distributed traces (without sampling)
- Request/response and header content per session, including from inside the system components (e.g., going from one service to another)
Using this category of tools, developers can see how a sequence of user actions triggered API calls and precisely how requests propagated through the backend system.


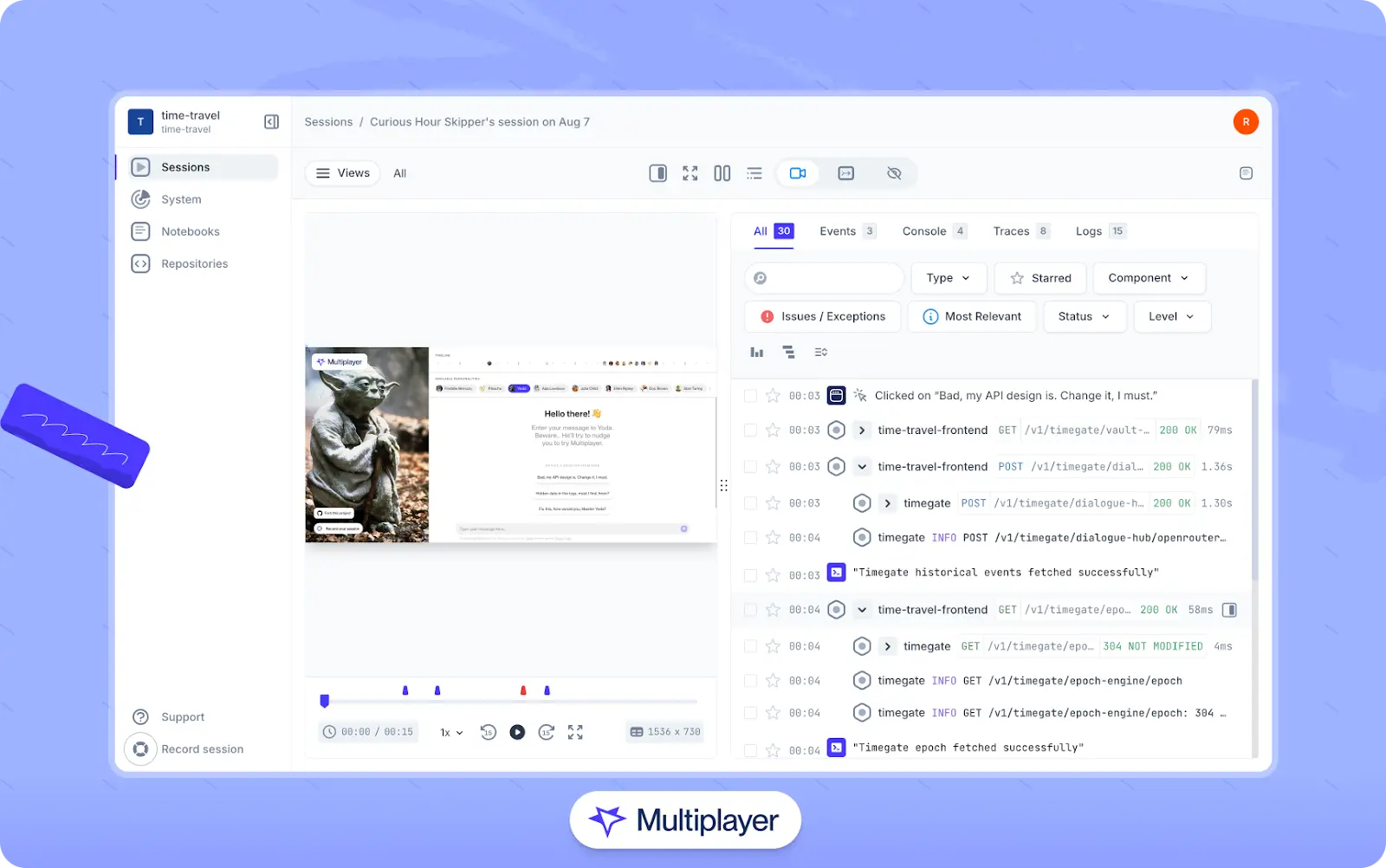
Multiplayer full stack session recordings
Conclusion
System design is a broad topic with many considerations. Although system design should begin with some degree of upfront planning, designing distributed systems is a complex, iterative process that should be revisited and refined over time.
Engineers and architects hoping to design reliable, resilient, and maintainable distributed systems must take into account numerous factors, such as different design patterns, data storage techniques, scalability strategies, and performance considerations. In doing so, development teams are empowered to create applications that respond to the unpredictabilities of the modern digital world.