Guide
System Architecture Design: Tutorial & Best Practices
Table of Contents
Distributed systems are the backbone of countless applications and services. Designed to handle large amounts of data and traffic across multiple nodes, modern distributed systems are instrumental in delivering seamless user experiences and ensuring scalability. However, with this complexity comes the critical challenge of designing robust and efficient system architectures that meet the demands of distributed environments.
This article explores the fundamental principles and nuances of system architecture design, including the key considerations, challenges, and best practices for developers and architects who work with distributed systems.
Summary of key system architecture design concepts
The table below summarizes the system architecture design concepts this article will explore.
| Concept | Description |
|---|---|
| Considerations for distributed system architecture | Designing distributed systems requires a nuanced understanding of various factors, from data consistency and fault tolerance to load balancing and latency management. |
| System architecture styles | When designing system architectures, consider different architectural styles, such as monolithic, microservices, event-driven, serverless, edge computing, and peer-to-peer. |
| Upfront vs. agile design: striking the right balance | Upfront design provides a structured foundation, while agile design ensures adaptability to evolving requirements. Striking a balance between these two practices fosters a dynamic and efficient approach to crafting resilient distributed systems. |
| Best practices for effective system architecture design | Practices like choosing the proper communication protocols and implementing robust error-handling mechanisms help architects navigate the intricacies of distributed system design. |
| Challenges on the horizon | While distributed systems offer unprecedented benefits, they also pose formidable challenges. Issues such as network partitions, data synchronization, and ensuring security in a decentralized environment are among the hurdles that architects must overcome. |
Considerations in a distributed system architecture
Several crucial considerations must be taken into account when designing distributed system architectures to ensure seamless functionality, scalability, and robustness. Complexities are inherent in distributed systems, where multiple interconnected components collaborate to achieve a common goal. This necessitates a thoughtful approach to addressing system design challenges.
Here are key considerations that guide the development of distributed systems:
- Fault tolerance and reliability: Implement redundancy and failover mechanisms to mitigate the impact of component failures. Employ distributed consensus algorithms to ensure consistency and reliability in the face of node outages or communication failures.
- Scalability: Design the architecture to accommodate growth regarding users, data, and processing demands. Consider horizontal scaling by adding more nodes and vertical scaling by enhancing individual node capabilities.
- Data consistency: Based on the system's requirements, choose an appropriate consistency model to balance the tradeoffs between strong and eventual consistency. Leverage techniques such as versioning or conflict resolution mechanisms to handle concurrent updates across distributed nodes.
- Security: Implement robust authentication and authorization mechanisms to safeguard data and system resources. Encrypt communication channels and data at rest to protect against unauthorized access and data breaches.
- Load Balancing: Distribute incoming requests evenly across multiple servers to prevent overloading individual nodes. Employ dynamic load-balancing strategies that adapt to changing workloads and network conditions.
- Monitoring and Logging: Incorporate comprehensive monitoring and logging mechanisms to track system performance, identify bottlenecks, and facilitate debugging. Integrate centralized logging systems to aggregate logs from various components for streamlined analysis.
Balancing these factors is essential to creating a resilient and efficient distributed system that meets the demands of modern, dynamic applications.
System architecture styles
System architecture styles encompass various approaches and methodologies for designing and structuring complex software systems. These principles dictate how components and subsystems are organized, interact, and function within the larger system. From monolithic architectures to microservices, each design style offers unique benefits and trade-offs, influencing scalability, maintainability, and deployment agility.
By understanding and applying different architecture styles, software architects can tailor solutions to meet specific requirements, optimize performance, and adapt to evolving technological landscapes. Here are several architecture styles commonly used in distributed systems:
Monolithic architecture


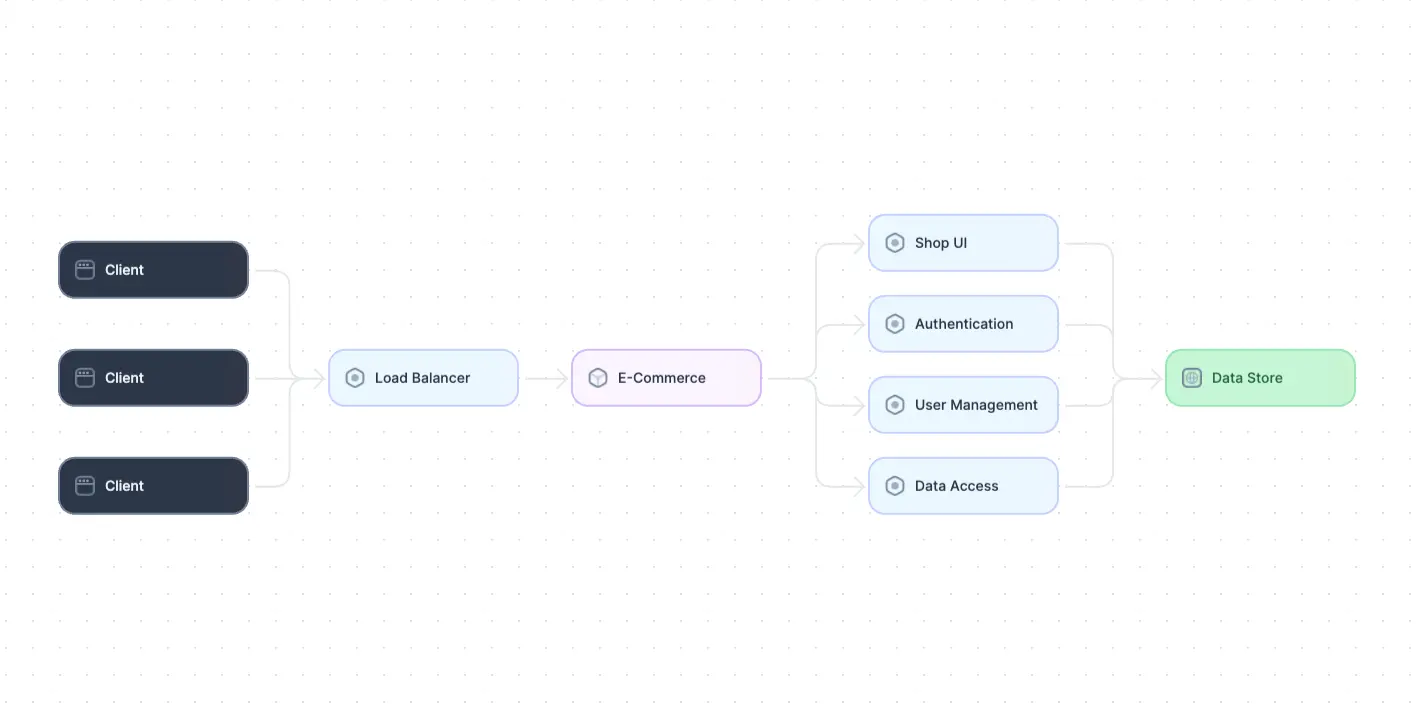
Diagram of a monolithic architecture (Adapted from Source)
In a distributed system, a monolithic architecture involves deploying the entire application as a single unit across multiple nodes or servers. Each node runs the complete stack of the application, including the user interface, business logic, and data access layers. Communication between nodes typically occurs via network protocols, and load-balancing techniques may be employed to distribute incoming requests among the nodes.
Advantages of a monolithic architecture:
- Simplicity: Monolithic architecture simplifies development and deployment processes by encapsulating all functionality within a single codebase, making it easier to understand and manage.
- Performance: Direct method calls within the monolith typically result in faster execution than inter-service communication in distributed architectures, enhancing overall performance.
- Ease of testing: Testing a monolithic application is often more straightforward since all components are tightly integrated, simplifying unit testing, integration testing, and debugging processes.
- Deployment simplicity: Deploying a monolithic application involves deploying a single artifact, reducing the complexity of managing multiple services and dependencies.
Considerations for monolithic architectures:
- Scalability challenges: Monolithic architectures can face scalability limitations, as scaling requires replicating the entire application rather than individual components, leading to inefficient resource utilization.
- Maintainability: Large monolithic codebases can become unwieldy and difficult to maintain over time, making it challenging to introduce changes or updates without impacting other parts of the system.
- Technology lock-in: Monolithic architectures are often tightly coupled to specific technologies, frameworks, or libraries, making it challenging to adopt new technologies or scale components independently.
- Limited deployment flexibility: Deploying changes to a monolithic application typically requires downtime or rolling updates, which can impact availability and user experience to a greater extent compared with deploying changes to independent services within a microservices architecture.
Microservices architecture


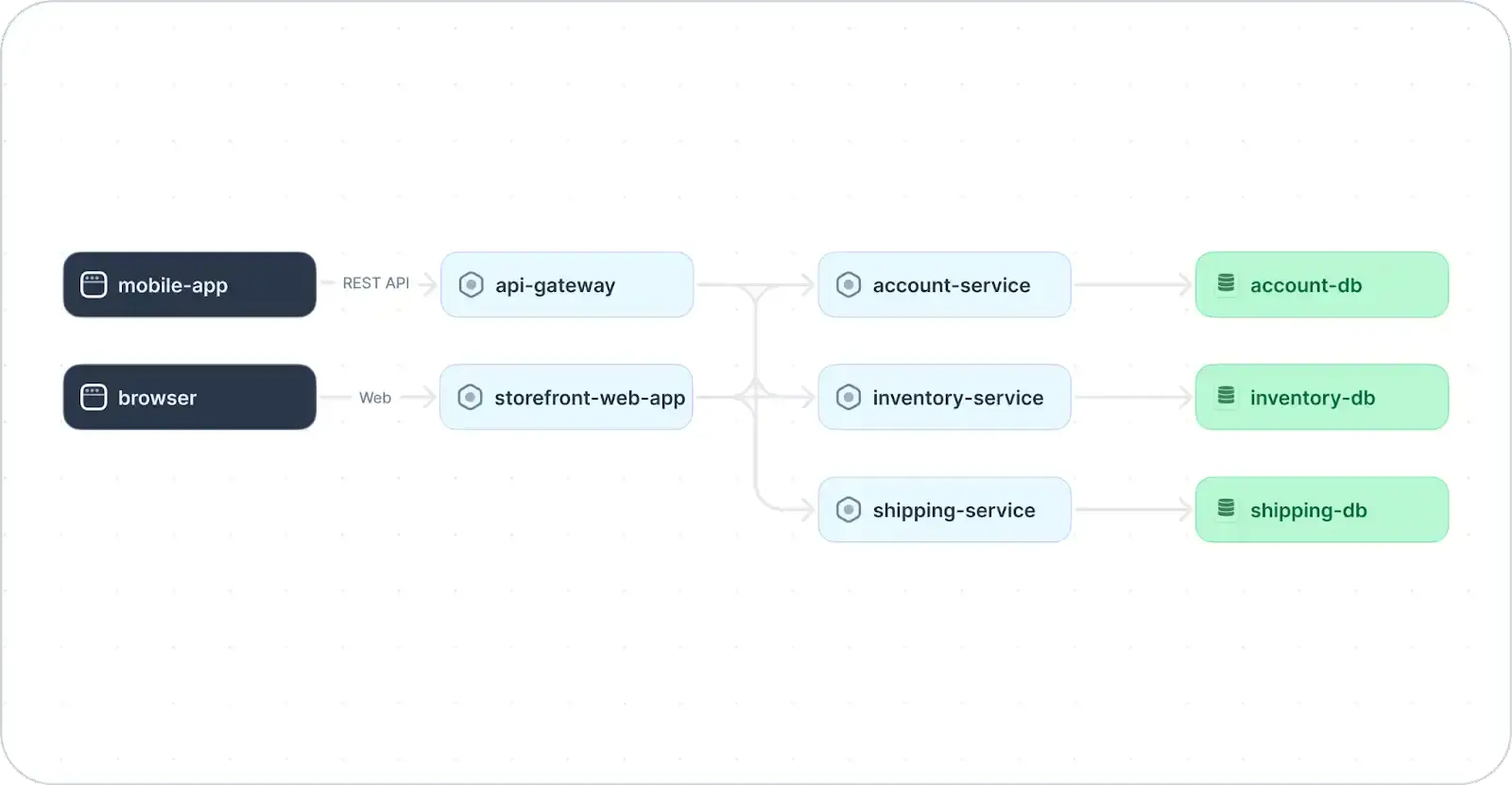
Typical implementation of microservices (adapted from Source)
In a microservices architecture, the system is decomposed into small, independent services that communicate through well-defined APIs and interfaces. Each service is typically responsible for a specific business capability.
Advantages of a microservices architectures:
- Scalability: Microservices architectures allow individual components to be scaled independently, enabling efficient resource allocation and effective handling of varying workloads.
- Flexibility and agility: Microservices promote flexibility by decoupling components, allowing teams to develop, deploy, and update services independently. This agility can facilitate faster time-to-market and easier experimentation with new features.
- Resilience and fault isolation: Failure in one microservice typically does not affect the entire system, as services are isolated. This enhances resilience and fault tolerance, ensuring that the failure of one component does not cascade into a system-wide outage.
- Tech stack diversity: Microservices enable different technologies, languages, and frameworks for each service, allowing teams to choose the most appropriate tools for specific tasks or domains.
Full-stack session recording
Learn more





Considerations for microservices architecture:
- Complexity: Microservices architectures introduce complexity in terms of service discovery, communication, and orchestration. Managing many services and dependencies can increase operational overhead and require sophisticated tooling.
- Distributed systems challenges: Distributed systems pose latency, consistency, and reliability challenges. Implementing robust communication protocols, error handling mechanisms, and distributed tracing is essential to effectively address these challenges.
- Data management complexity: Microservices often lead to distributed data management, requiring careful consideration of data consistency, transactions, and synchronization across services. Distributed data stores or event-driven architectures can help manage data complexity.
- Operational overhead: Operating and managing a microservices-based system can be complex, requiring expertise in containerization, orchestration, monitoring, and automation. DevOps practices and tooling are essential to streamline deployment, monitoring, and management processes.
Event-driven architecture


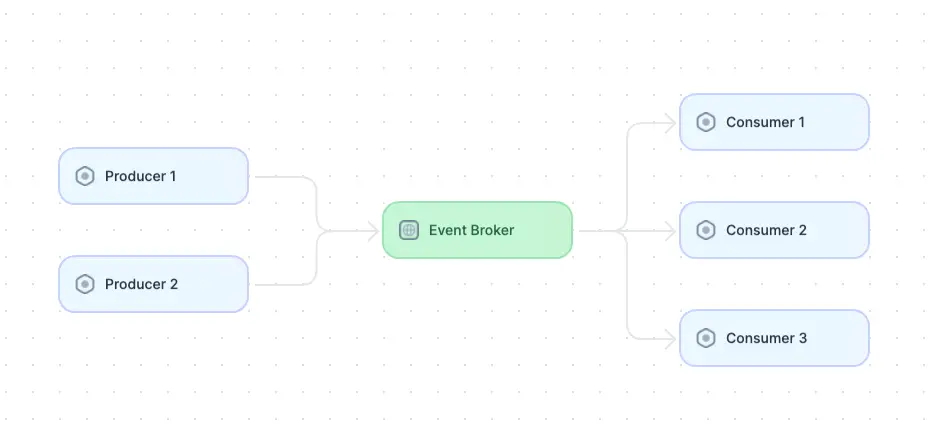
Diagram of an event-driven architecture (adapted from Source)
In an event-driven architecture, components are decoupled and communicate asynchronously through the exchange of events. Different components can produce, consume, or process events, allowing for loose coupling and flexibility in system design. Components typically include event producers, event consumers, and brokers (or event routers).
Advantages of an event-driven architecture:
- Asynchronous communication: Event-driven architecture facilitates asynchronous communication between components, allowing services to react to events and messages in real time without blocking each other or waiting for responses.
- Scalability: Event-driven systems are inherently scalable, as components can process events independently and concurrently. This enables horizontal scalability, where additional event processors can be added to handle increased event throughput.
- Flexibility and decoupling: Event-driven architecture promotes loose coupling between components, as services communicate through events rather than direct method calls. This decoupling enables services to evolve independently, reducing dependencies and simplifying system maintenance.
- Fault isolation: Failure in one component typically does not impact the entire system, as services are decoupled and operate independently. This enhances fault isolation and resilience, ensuring that failures are contained and do not propagate through the system.
Considerations for event-driven architectures:
- Complexity: Event-driven architectures introduce complexity regarding event processing, event sourcing, and event-driven workflows. Managing event flows, handling out-of-order events, and ensuring message delivery reliability can increase system complexity.
- Eventual consistency: Event-driven systems may exhibit eventual consistency, where different components may have divergent views of the system state until events are fully propagated and processed. Implementing mechanisms for conflict resolution and eventual consistency is essential to maintain data integrity.
- Message ordering: Maintaining message order can be challenging in event-driven architectures, especially in distributed environments with asynchronous communication. Implementing mechanisms such as event sequencing, message timestamps, or event versioning is necessary to preserve message order when required.
- Debugging and monitoring: Debugging and monitoring event-driven systems can be challenging due to the asynchronous nature of event processing. Implementing comprehensive logging, monitoring, and tracing mechanisms is essential to diagnose issues, track event flows, and ensure system reliability.
Serverless architecture


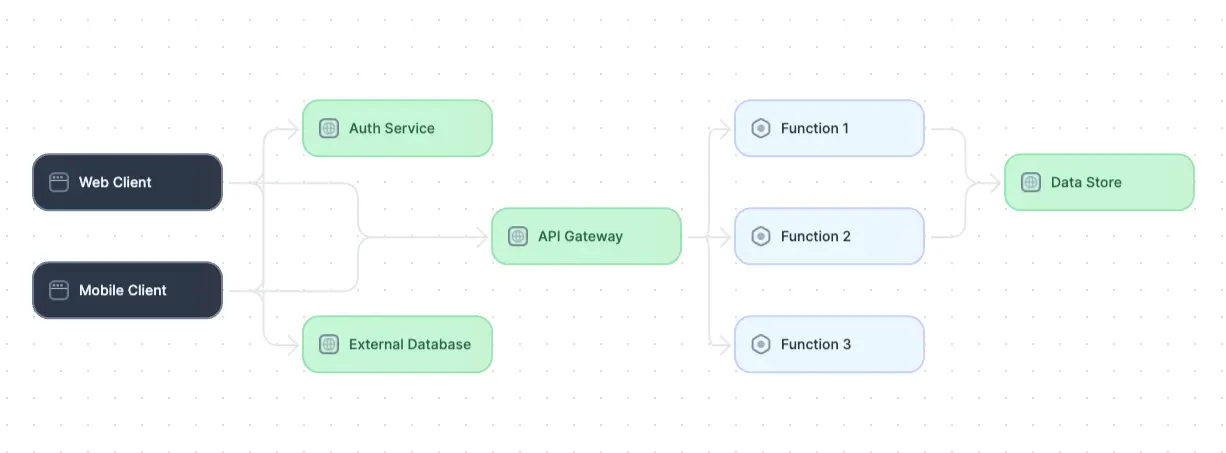
Diagram of a serverless architecture (adapted from Source)
In serverless architecture, developers focus on writing discrete, event-driven functions that perform specific tasks or handle particular events. These functions are deployed to a cloud provider's serverless platform and automatically scaled up or down based on demand. The cloud provider manages infrastructure provisioning, scaling, and maintenance, allowing developers to focus on writing code without worrying about server management.
Advantages of a serverless architecture:
- Scalability: Serverless architectures automatically scale to handle varying workloads as cloud providers manage the underlying infrastructure and resources. This enables applications to scale seamlessly without manual intervention or provisioning additional servers.
- Cost efficiency: Serverless architectures offer a pay-per-use pricing model, where users are only charged for the resources consumed during execution. This can save costs compared to traditional server-based architectures, especially for sporadic or unpredictable workloads.
- Reduced operational complexity: Serverless architectures abstract away infrastructure management tasks such as server provisioning, scaling, and maintenance, allowing developers to focus on application logic rather than infrastructure management.
- Faster time to market: Serverless architectures promote rapid development and deployment cycles. Developers can quickly build and deploy functions or services without worrying about infrastructure setup or configuration, accelerating time to market for new features and updates.
Considerations for serverless architectures:
- Vendor lock-in: Adopting serverless architectures may result in vendor lock-in, as applications become tightly coupled to specific cloud providers' services and APIs. This can limit portability and flexibility, making migrating applications to alternative platforms challenging.
- Cold start latency: Serverless architectures may experience cold start latency, where the initial invocation of a function or service incurs additional overhead due to resource provisioning and initialization. This can impact application performance, especially when processing latency-sensitive workloads.
- Limited execution environment: Serverless platforms restrict execution environments, such as maximum execution duration, memory limits, and available runtime environments. Developers must ensure that their functions or services comply with these constraints to avoid performance degradation or runtime errors.
- Monitoring and debugging challenges: Monitoring and debugging serverless applications can be challenging due to serverless functions' distributed and ephemeral nature. Implementing robust logging, monitoring, and debugging tools is essential to diagnose issues, track performance metrics, and ensure application reliability.
Edge computing architecture


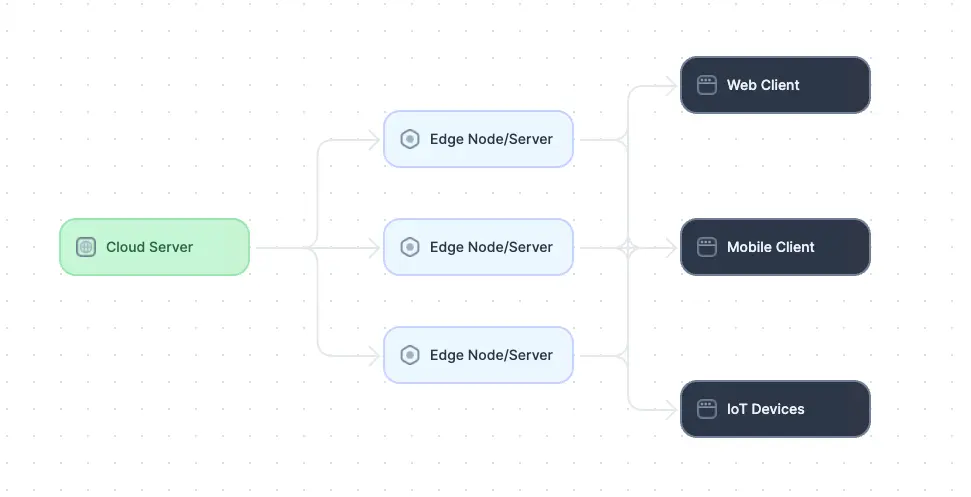
Diagram of an edge-computing architecture (adapted from Source)
Edge computing architecture involves deploying computing resources, including servers, storage, and networking equipment, closer to the network's edge, such as IoT devices, mobile devices, or local data centers. This architecture enables data processing, analysis, and storage to occur locally, reducing the need to transmit large volumes of data to centralized cloud servers for processing.
Advantages of an edge computing architecture:
- Reduced latency: Edge computing architecture brings computation closer to the data source or end-users, minimizing latency by processing data locally. This results in faster response times and improved user experiences, particularly for latency-sensitive applications like IoT, AR/VR, and real-time analytics.
- Bandwidth optimization: By processing data locally at the edge, edge computing reduces the need to transmit large volumes of data to centralized cloud servers, optimizing bandwidth usage and reducing network congestion. This is particularly beneficial for applications serving users with limited bandwidth or unreliable network connectivity.
- Improved reliability: Edge computing enhances reliability by distributing computation and storage across multiple edge nodes or devices. This redundancy ensures that applications remain operational even during network disruptions, server failures, or other localized outages.
- Data privacy and security: Edge computing architecture improves privacy and security by processing sensitive data locally, closer to the data source or end user. This reduces the risk of data exposure during transit to centralized cloud servers and enables stricter control over data access and compliance with regulatory requirements.
Interact with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
Considerations for edge computing architectures:
- Infrastructure complexity: Deploying and managing edge computing infrastructure requires coordination across distributed edge nodes, devices, and networks. Ensuring interoperability, standardization, and compatibility among heterogeneous edge devices and platforms is essential to streamline deployment and management processes.
- Resource constraints: Edge devices and nodes often need more computational resources, memory, and storage capacity. Designing and optimizing applications within these resource constraints is crucial for efficient edge computing.
- Network connectivity: Edge computing relies on reliable, low-latency network connectivity to transmit data between edge devices, nodes, and centralized cloud servers. Ensuring robust network infrastructure, protocols, and mechanisms for edge-to-cloud communication is essential to effectively implement edge computing applications.
- Security risks: Edge devices and nodes deployed in physically insecure environments are susceptible to various security threats, including unauthorized access, tampering, and data breaches. Implementing robust security measures, such as encryption, authentication, and access controls, is essential to mitigate security risks and ensure the integrity and confidentiality of data and communications at the edge.
Peer-to-peer architecture


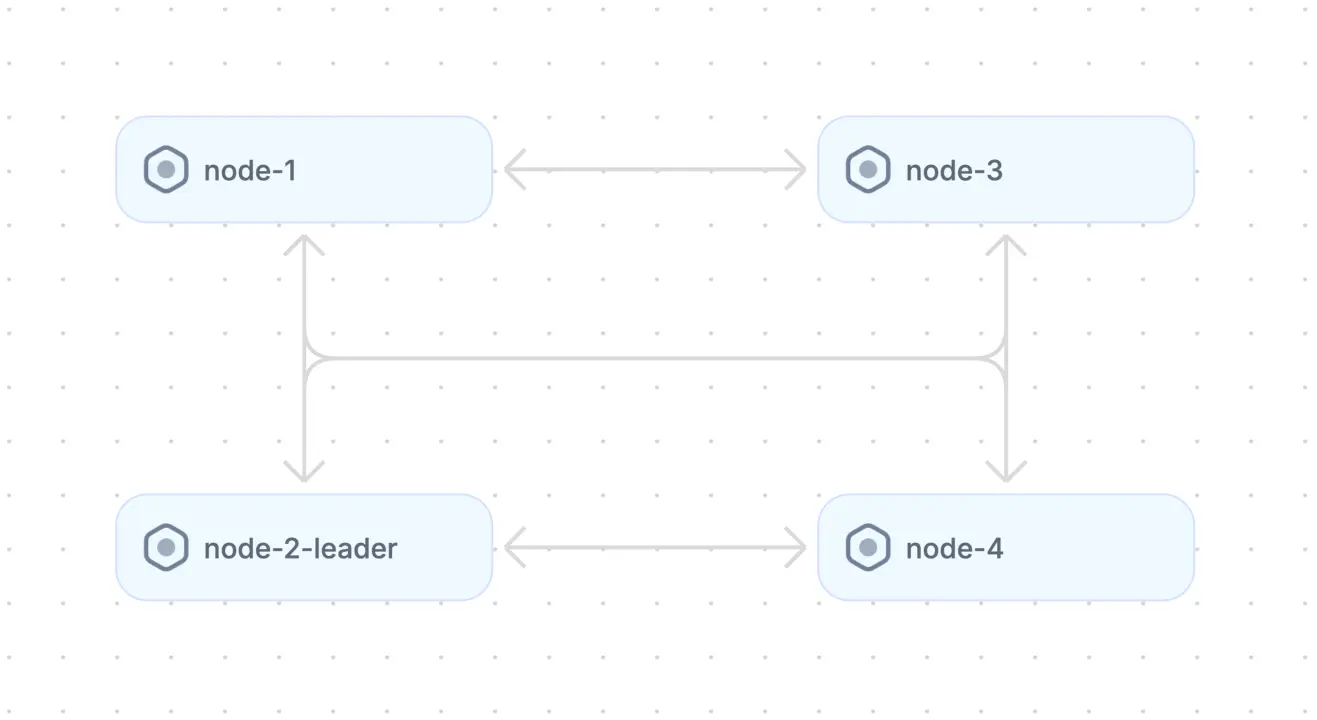
Diagram of peer-to-peer architecture (adapted from Source)
In a peer-to-peer architecture, each peer has equal capabilities and can act as both a client and a server, contributing resources and services to the network while also accessing resources provided by other peers. Peers communicate directly with each other, often using overlay networks or distributed hash tables (DHTs) to facilitate peer discovery, routing, and data sharing.
Advantages of peer-to-peer architecture:
- Decentralization: Peer-to-peer architecture distributes control and resources across participating nodes, eliminating the need for centralized servers. This decentralization enhances system resilience, fault tolerance, and scalability by reducing single points of failure and bottlenecks.
- Scalability: Peer-to-peer systems can scale dynamically by adding more nodes to the network, enabling efficient resource allocation and better handling of increasing workloads. This scalability is particularly beneficial for applications with unpredictable or fluctuating demand.
- Efficient resource utilization: Peer-to-peer architectures leverage resources distributed across multiple nodes, enabling efficient utilization of computing power, storage, and bandwidth. This distributed resource-sharing model promotes collaboration, diversity, and inclusiveness, empowering participants to contribute and benefit from collective resources.
- Privacy and anonymity: Peer-to-peer architectures offer enhanced privacy and anonymity compared to centralized architectures, as communication between peers often occurs directly without intermediaries. Peers can exchange data and communicate without revealing their identities, enhancing privacy and security.
Considerations for peer-to-peer architectures:
- Network overhead: Peer-to-peer architectures may incur higher network overhead than client-server architectures, as peers communicate directly and exchange messages to discover, connect, and share resources. Efficient overlay network algorithms and protocols are necessary to minimize overhead and optimize communication.
- Data consistency: Ensuring data consistency and coherence in peer-to-peer networks can be challenging, especially when peers operate autonomously and asynchronously. Implementing distributed consensus algorithms, replication strategies, and conflict resolution mechanisms is necessary to maintain data integrity and consistency across the network.
- Security risks: Peer-to-peer networks are vulnerable to various security threats, including malicious attacks, unauthorized access, and data manipulation. Peers must implement robust security measures, such as authentication, encryption, and access control, to protect against security risks and ensure the integrity and confidentiality of data and communications.
- Performance and reliability: Peer-to-peer architectures may face challenges related to performance and reliability, especially in large-scale networks with heterogeneous peers and dynamic resource availability. Optimizing peer selection, load balancing, and resource allocation algorithms is crucial to ensure optimal performance and reliability across the network.
Upfront vs agile design: striking the right balance
Choosing between big upfront design and agile design methodologies is a persistent challenge in software development. Each approach has its own merits and drawbacks, and striking the right balance between the two is essential for successful project outcomes. The following sections explore the characteristics of upfront design and agile methodologies and how harmoniously integrating both can enhance the software development process.
Upfront design
Upfront design, often associated with the traditional waterfall model, involves a comprehensive planning phase before coding begins. This phase includes gathering requirements, creating detailed specifications, and establishing a thorough architecture. Some pros and cons of this approach are summarized in the table below.
| Pros | Pros |
|---|---|
| Clear roadmap: Upfront design provides a well-defined plan, minimizing uncertainties and providing timeline and budget estimates. | Rigidity: There is limited flexibility in accommodating changes once the development phase has started. |
| Early risk mitigation: Identifying potential issues in the design phase mitigates the risks of implementing inefficient or ineffective designs. | Lengthy planning: Elaborate upfront planning may extend the time before actual development begins. |
| Detailed documentation: This approach usually leads to comprehensive documentation, which aids in understanding the system's architecture and design decisions. | Adaptability: Teams using this approach may struggle to adapt to changing requirements or evolving project scopes. |
Agile methodologies
Agile methodologies, on the other hand, embrace flexibility and iterative development. Agile promotes collaboration, adaptability, and the delivery of functional software in smaller, incremental cycles. This approach accommodates changing requirements and encourages customer feedback throughout the development process. Here are some pros and cons of agile methodologies:
| Pros | Cons |
|---|---|
| Flexibility: Agile allows for quick adaptation to changing requirements and priorities. | Lack of initial clarity: Limited upfront planning may result in uncertainty about the overall system architecture. |
| Continuous feedback: Regular iterations facilitate ongoing feedback from stakeholders. | Risk of scope creep: Frequent changes could lead to scope creep and project instability. |
| Early deliverables: Agile design enables delivering functional, usable features early in the development cycle. | Documentation challenges: Agile design's emphasis on working software can result in less comprehensive documentation unless the right tools and practices are implemented. |
Striking the right balance
Balancing upfront design and agile methodologies involves recognizing the project's nature, size, and requirements. For larger projects with well-understood and stable requirements, a greater degree of upfront design will likely be beneficial. However, it is crucial to keep in mind that application requirements evolve over time, and it is not possible to plan for every eventuality.
Therefore, we recommend beginning with an initial upfront design phase to establish a solid foundation, followed by iterative development cycles using agile methodologies to accommodate evolving needs.
Key strategies
- Planning ahead: Include some level of upfront system design for any significant system change, such as new features, refactoring, or bug fixes.
- Collaborative communication: Foster effective communication between developers, stakeholders, and end users.
- Flexibility within constraints: Define constraints and boundaries to allow for adaptability while maintaining project stability.
- Continuous improvement: Embrace a culture of continuous improvement, learning from each iteration to enhance subsequent design phases.
Finding the right balance involves understanding the project's context, embracing adaptability, and leveraging the strengths of both upfront design and agile methodologies throughout the software development lifecycle.
Nine essential system architecture design best practices
Designing effective distributed system architectures involves adhering to best practices to ensure scalability, reliability, and maintainability. Here are some fundamental guidelines:
Embrace modularity and decomposition
Decompose the system into smaller, loosely coupled modules or services. This promotes scalability, allows for independent development and deployment, and facilitates more manageable maintenance and updates.
Define service boundaries and API contracts
Clearly defined service boundaries and well-defined API contracts between services ensure proper encapsulation, enable interoperability, and promote flexibility in evolving system components.
Leverage asynchronous communication
Favor asynchronous communication patterns to decouple system components and reduce dependencies. Asynchronous communication patterns offer advantages over traditional tightly coupled communications by decoupling components and enabling non-blocking interactions. This allows systems to handle concurrent tasks more efficiently, improving scalability, responsiveness, and fault tolerance. Additionally, asynchronous communication will enable systems to adapt to workloads and network conditions, enhancing flexibility and resilience in distributed environments.
Enforce strong security and access controls
Prioritize security considerations throughout the design process. Implement robust authentication, authorization, and encryption mechanisms to protect sensitive data and prevent unauthorized access. Follow security best practices and stay updated on emerging threats and vulnerabilities.
Implement fault tolerance and resilience
Fault tolerance and resilience are critical aspects of system architecture design, ensuring that distributed systems can maintain functionality and availability despite component failures or unexpected events. Fault tolerance involves designing systems to anticipate, tolerate, and recover from failures gracefully, while resilience focuses on the system's ability to adapt and recover quickly from disruptions.
In system architecture, fault tolerance strategies include redundancy, replication, and failover mechanisms to mitigate the impact of component failures. Redundancy involves duplicating critical components or resources to ensure another node can seamlessly take over if a component or resource fails. Replication extends this concept by distributing data or services across multiple nodes, allowing for seamless failover and load balancing. Failover mechanisms automatically redirect traffic or workload to backup components or resources in the event of failure, ensuring continuous operation.
Resilience in system architecture involves designing systems to detect and respond to failures proactively, dynamically adjusting to changing conditions to maintain functionality. This may include implementing self-healing mechanisms–such as automatic recovery, adaptive routing, or dynamic resource allocation–to adapt to failures and fluctuations in workload or environment. By incorporating fault tolerance and resilience into system architecture design, organizations can build robust and reliable distributed systems capable of withstanding failures and providing uninterrupted service to users.
One click. Full-stack visibility. All the data you need correlated in one session
RECORD A SESSION FOR FREEAccount for scalability
Designing for scalability ensures that applications can handle increasing workloads and accommodate growth without sacrificing performance or reliability. For applications with relatively stable user bases, vertical scaling can be an effective approach. Scaling vertically involves upgrading hardware or reconfiguring cloud resources for increased CPU, memory, storage, network speed, or other resources.
However, in the context of a large, distributed application with a large or growing user base, organizations typically employ horizontal scaling. This approach allows systems to scale out by adding more machines or nodes to distribute the workload effectively. When implementing horizontal scaling, the following techniques are crucial:
- Sharding: dividing the dataset into smaller subsets and distributing them across multiple nodes, allowing each node to handle a portion of the workload independently.
- Partitioning: dividing the workload into smaller segments (partitions), ensuring that different nodes can process different subsets of data concurrently.
- Replication: creating and maintaining copies of data or resources across multiple systems, nodes, or locations. This technique can improve data availability, reliability, and performance.
Understand consistency models and their tradeoffs
Consistency models govern how data consistency is maintained across nodes in a distributed system. They define the rules and guarantees regarding the visibility of data changes to different nodes in the system. Two common consistency models and their tradeoffs are summarized in the table below.
| Model | Description | Tradeoffs |
|---|---|---|
| Strong consistency | All nodes see the same data simultaneously, even in the presence of concurrent updates or failures. | Requires complex coordination mechanisms, such as distributed transactions or consensus protocols, which can introduce latency and reduce system performance |
| Eventual consistency | Data updates propagate asynchronously across distributed nodes, and all nodes eventually converge to the same state. | Offers high availability and scalability but may result in temporary inconsistencies or divergent data views across nodes. |
In distributed system architecture design, the choice of consistency model depends on various factors, including application requirements, performance goals, and trade-offs between consistency, availability, and partition tolerance (CAP theorem). For latency-sensitive applications or scenarios where temporary inconsistencies are acceptable, eventual consistency may be preferred. In contrast, applications requiring strict consistency guarantees, such as financial transactions or critical systems, may opt for strong consistency despite the associated performance overhead.
Furthermore, hybrid consistency models and techniques, such as causal consistency or eventual consistency with causal ordering, offer nuanced approaches to balancing consistency and performance in distributed systems. By carefully selecting and configuring consistency models, architects can design distributed systems that meet the specific needs of their applications while optimizing for performance, availability, and reliability.
Select the right data partitioning and distribution approach
Data partitioning and distribution are crucial considerations in distributed system architecture design, particularly for managing large datasets efficiently across distributed nodes. Partitioning involves dividing the dataset into smaller subsets, or partitions, and distributing them across multiple nodes in the system.
Architects can optimize data access, query performance, and resource utilization in distributed systems by carefully selecting and implementing data partitioning and distribution strategies. Effective data partitioning facilitates scalability, fault tolerance, and parallel processing, enabling distributed systems to efficiently manage and process large datasets across distributed nodes while minimizing latency and maximizing performance.
Several strategies exist to achieve effective data partitioning and distribution, each offering unique benefits and trade-offs as follows:
Hash-based partitioning
In this approach, a hash function is applied to each data item's key to determine its partition assignment. Data items with the same key are consistently routed to the same partition.
Hash-based partitioning facilitates efficient data retrieval and aggregation, is simple to implement, and offers uniform data distribution. However, if the keys are not evenly distributed, this approach may result in uneven data distribution.
Range-based partitioning
This approach partitions data based on a predefined range of keys. Data items within a specific key range are stored together in the same partition.
Range-based partitioning can improve locality and query performance for range-based queries. However, if the key ranges are not evenly distributed, it may lead to hotspots or uneven data distribution.
Hybrid
A hybrid approach combines hash-based and range-based partitioning techniques to balance uniform data distribution and efficient range queries. Data is partitioned using a hash function to achieve uniform distribution and subdivided into ranges within each partition to optimize range-based queries.
Implementing hybrid partitioning introduces complexity in managing multiple partitioning schemes, coordinating data movement, and ensuring consistency across partitions. This complexity may increase operational overhead and development effort and introduce potential points of failure or performance bottlenecks.
Other approaches
Partitioning can also be performed based on data characteristics such as access patterns, workload distribution, or geographic location. Geographic partitioning, for example, involves partitioning data based on the geographic location of users or resources, enabling data locality and reducing network latency for geographically distributed applications.
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREECreate documentation and foster communication
Clear documentation keeps decisions transparent and ensures everyone understands requirements, constraints, and how the system behaves in production. Document design decisions and protocols to create a shared reference point, and make sure the documentation stays aligned with the system as it changes.
In addition, use tools that help developers link documentation to runtime behavior and embed artifacts like system requirements, system design decisions, Architectural Decision Records (ADRs), and technical debt alongside executable code and API blocks. Doing so keeps discussions in context and helps avoid gaps between design and implementation. Tools like Multiplayer make this possible with features such as dashboards, full-stack session recordings, and interactive, executable notebooks.


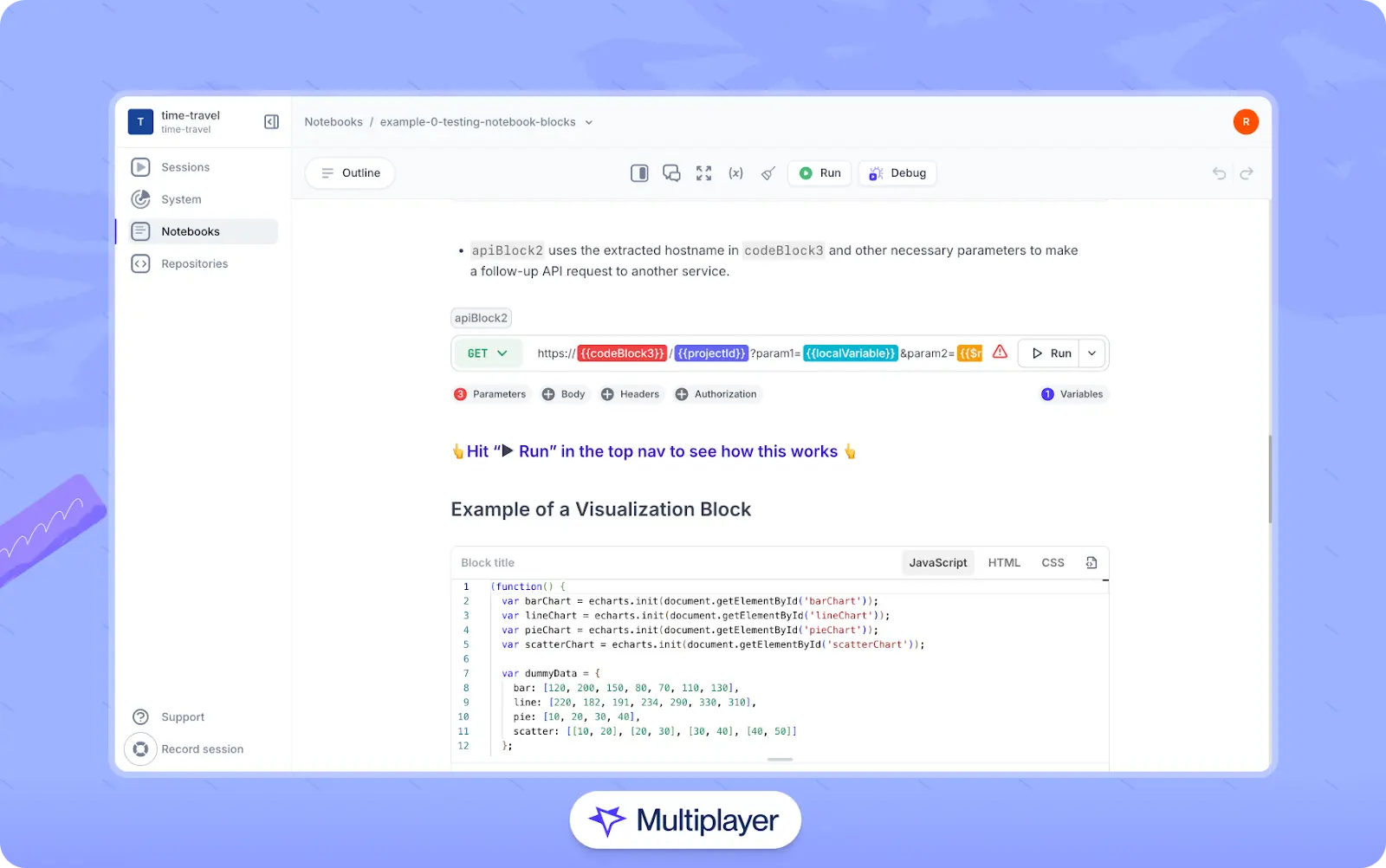
Multiplayer notebooks
Six emerging system architecture design challenges
As technology evolves, several challenges are emerging in system architecture design for distributed systems. Addressing these challenges is crucial for ensuring distributed systems' scalability, reliability, and efficiency.
Here are six key challenges on the horizon for developers and architects responsible for implementing and maintaining distributed system architectures:
- Scalability and performance optimization: With the increasing volume of data and the demand for real-time processing, scalability remains a significant challenge. Designing systems that can efficiently scale to handle growing workloads while maintaining optimal performance is essential.
- Distributed consistency and coordination: Achieving consistency in distributed systems without sacrificing performance is a complex challenge. Coordinating transactions and maintaining data consistency across distributed nodes, especially in the face of network partitions or failures, requires careful design and implementation.
- Security and privacy concerns: Distributed systems are susceptible to various security threats, including data breaches, unauthorized access, and distributed denial-of-service (DDoS) attacks. Addressing security and privacy concerns, such as data encryption, access control, and secure communication protocols, is critical for safeguarding sensitive information in distributed environments.
- Resource management and optimization: Effectively managing resources such as compute, storage, and network bandwidth in distributed systems presents challenges. Optimizing resource allocation, workload scheduling, and resource utilization to maximize performance and minimize costs requires advanced techniques and algorithms.
- Regulatory compliance and governance: Compliance with GDPR, HIPAA, and PCI DSS poses additional challenges for distributed systems, particularly concerning data privacy, security, and auditability. Ensuring regulatory compliance and implementing governance mechanisms to enforce policies and standards are essential considerations for system architects.
- Emerging technologies and paradigms: Keeping pace with emerging technologies and paradigms–such as edge computing, serverless architectures, and blockchain–introduces new challenges and opportunities for distributed system design. Evaluating the applicability and implications of these technologies in distributed environments requires ongoing research and experimentation.
Addressing these challenges requires a holistic approach to system architecture design, encompassing scalability, resilience, security, data management, and regulatory compliance. Collaboration among architects, developers, and domain experts, along with continuous learning and adaptation to evolving technologies and practices, is essential for overcoming these challenges and building robust and resilient distributed systems for the future. Modern platforms, such as Multiplayer, can help by providing shared dashboards, session recordings that capture real system behavior, and notebooks that connect design discussions to implementation details.
Final thoughts
Designing a distributed system architecture involves navigating myriad considerations, from fault tolerance and scalability to security and data consistency. Addressing these challenges requires a comprehensive approach, integrating best practices, leveraging appropriate system architecture styles, and remaining adaptable to evolving requirements and technologies. By embracing collaboration, continuous learning, and utilizing modern tooling platforms like Multiplayer, architects and developers can build resilient and efficient distributed systems capable of meeting the demands of modern applications.