Guide
Distributed Systems Design: Tutorial & Best Practices
Table of Contents
Distributed systems consist of independent software services that reside on separate computing units and coordinate with each other to achieve common goals. They are the backbone of modern SaaS products, which handle millions (or billions) of requests daily and, therefore, must be scalable, performant, and highly available.
Designing distributed systems presents several unique design challenges because of their loosely coupled and intrinsically asynchronous nature. At the component level, each distributed system node is a miniature system and must be equipped to handle its part of the system load independently of other components. At the application level, it is essential to ensure that the components of a distributed system can communicate reliably and effectively in the face of events like internal upgrades, network failures, service failures, and other uncommon or unforeseen scenarios. A distributed system must be designed with these challenges in mind to reduce the risk of catastrophic failures and data loss.
This article will explore common distributed systems design patterns that have evolved to address these challenges. Teams can use these design patterns to craft distributed systems that effectively address many modern use cases. We will also review seven practical distributed systems design best practices.
Summary of key distributed systems design patterns
The table below summarizes the distributed systems design patterns this article will explore in more detail.
| Design pattern | Description | Use cases |
|---|---|---|
| Ambassador | Single point of communication for application services that acts as a proxy to offload common tasks like logging, retries, and monitoring. | Most distributed environments in which multiple different types of services need to perform similar monitoring tasks. For example, envoy proxy in k8s. |
| Circuit breaker | Intelligent link between dependent services that stops traffic if it detects failures in the downstream service to prevent cascading failures. | Cloud-based distributed systems where multiple services are interdependent and network or other failures are relatively common. |
| Command query responsibility segregation (CQRS) | Uncoupling read and write queries into separate components so that each can scale independently. | Applications with significantly different read and write characteristics, such as e-commerce websites. |
| Event sourcing | Maintaining changes to records as an event log rather than directly modifying the current state of the record. | Systems that need a comprehensive history of changes over time, such as version-control systems. |
| Leader election | Multiple nodes in the system elect one as a "leader" with decision-making responsibilities. | Distributed systems are where a common set of tasks need to be divided among multiple copies of the same component (e.g., distributed databases like MongoDB). |
| Publisher/subscriber | Event publishers and subscribers are independent and communicate through a separate event distribution component. | Systems where the same type of event needs to be acted upon by multiple entities. |
| Sharding | Data is divided into identifiable subparts, or shards, between different nodes. | Database systems in which multiple nodes are deployed to decrease query latencies (e.g., Cassandra). |
Distributed system design patterns
This section will examine seven popular distributed systems design patterns and analyze specific systems or applications where these patterns can be useful. When designing a distributed system, it is helpful to be aware of these patterns so that architects can spot where they are needed and incorporate them into the system design in the early stages. This helps avoid costly overhauls to the system after resources have been provisioned and application code has been written and deployed.
Ambassador


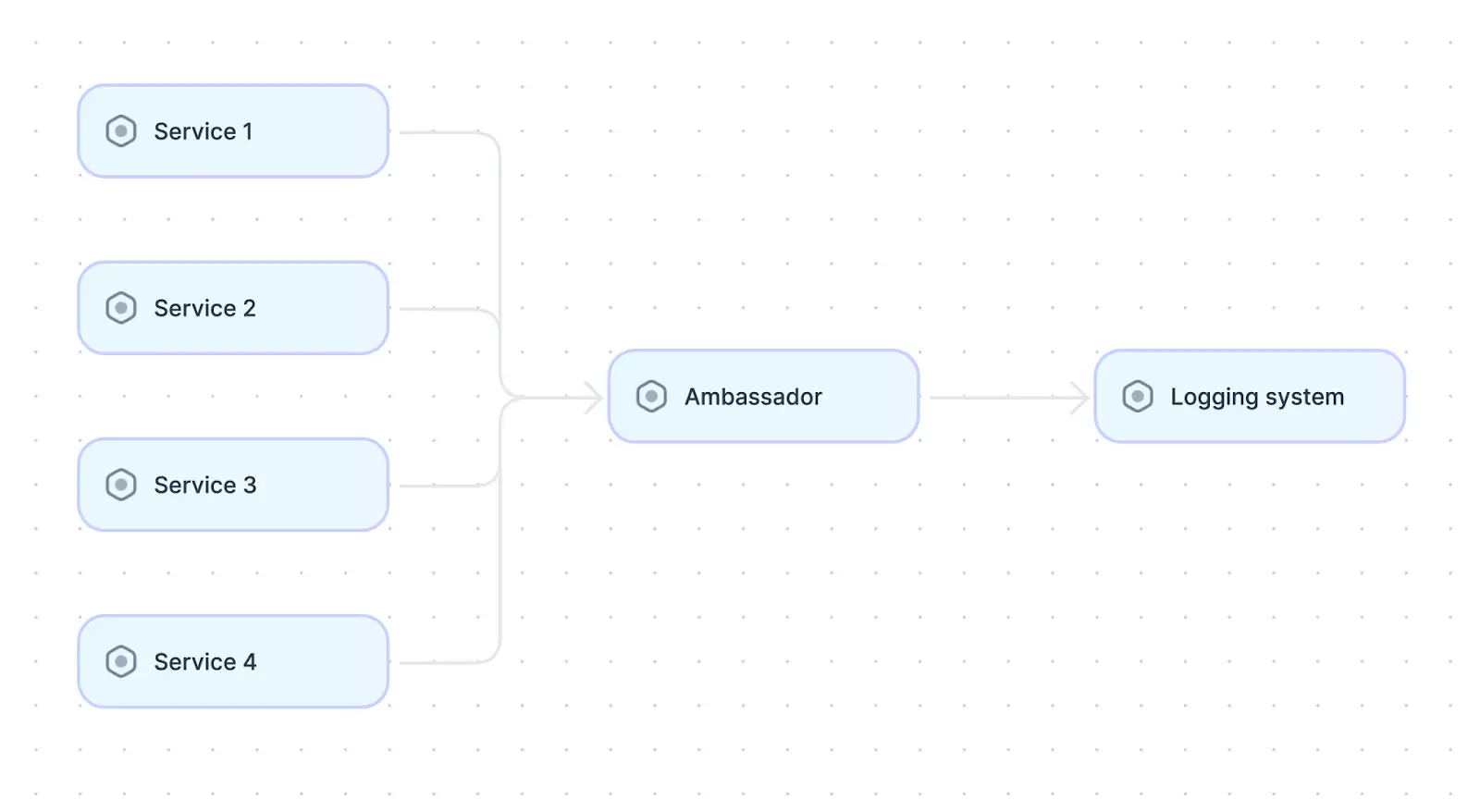
The ambassador design pattern is common in distributed systems.
In the ambassador pattern, the ambassador is a proxy service responsible for handling common tasks needed by all services of the distributed system. Some examples of such common tasks are logging, monitoring, and routing. All services make calls to the ambassador whenever they want to perform any of these tasks, and the ambassador handles them accordingly. This pattern removes the need for each service to handle these tasks individually, which improves the system’s efficiency and speeds up development. It also provides a single place to make changes across the system; for example, moving logs from a file to a system like Elasticsearch without changing each service becomes much less complex.
The ambassador pattern is helpful in most distributed systems because tasks like logging, monitoring, and routing are omnipresent. Teams can use this distributed systems design pattern as long as there is a service that is accessible from all other services in the system. An example of an ambassador is the Kubernetes envoy proxy, which handles routing and abstracts network complexities from the application..
Circuit breaker


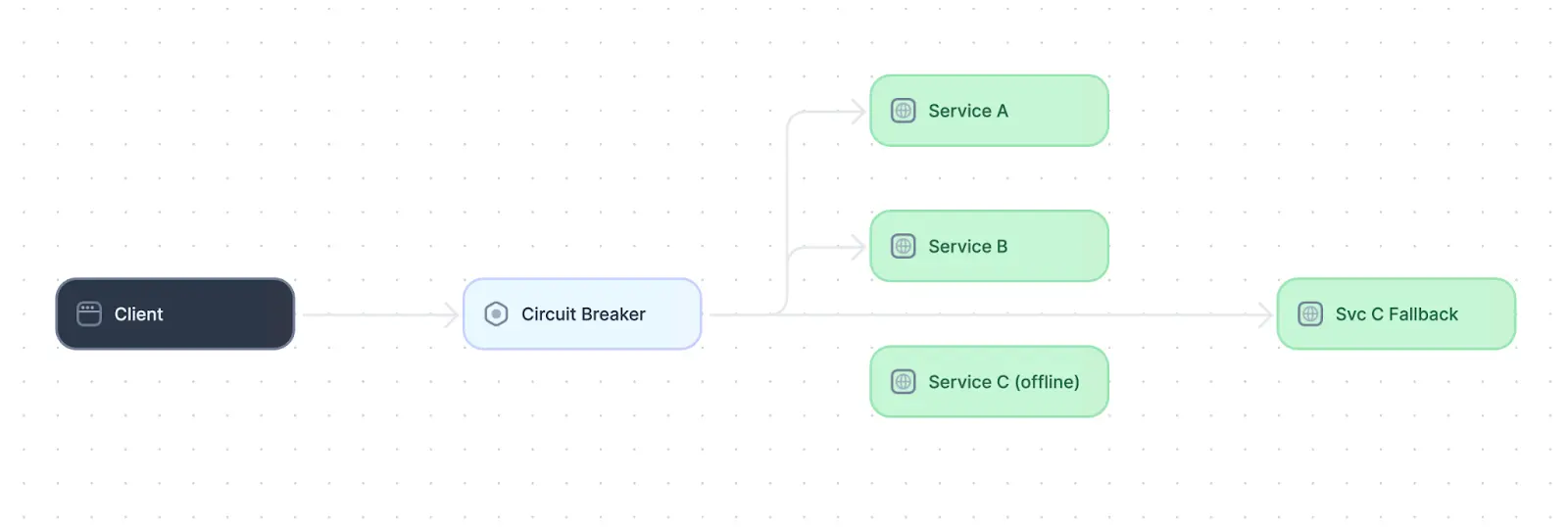
The circuit breaker design pattern common in distributed systems.
The circuit breaker pattern can be built into any distributed services that make calls to other services. If the circuit breaker detects that some calls to a downstream service are failing repeatedly over a certain threshold, it assumes that the downstream service has developed a failure and blocks those calls from being routed to the downstream service for a predetermined period. This prevents more significant failures that could arise if issues with one service were permitted to cascade through the entire system. Many modern communication frameworks, such as Hystrix and Spring Cloud, have built-in circuit-breaker functionality.
Circuit breakers are useful in complex systems where services are highly dependent on one another. For example, the circuit breaker pattern is ideal for cases where multiple services interact to complete user-facing functionalities.
Command query responsibility segregation (CQRS)


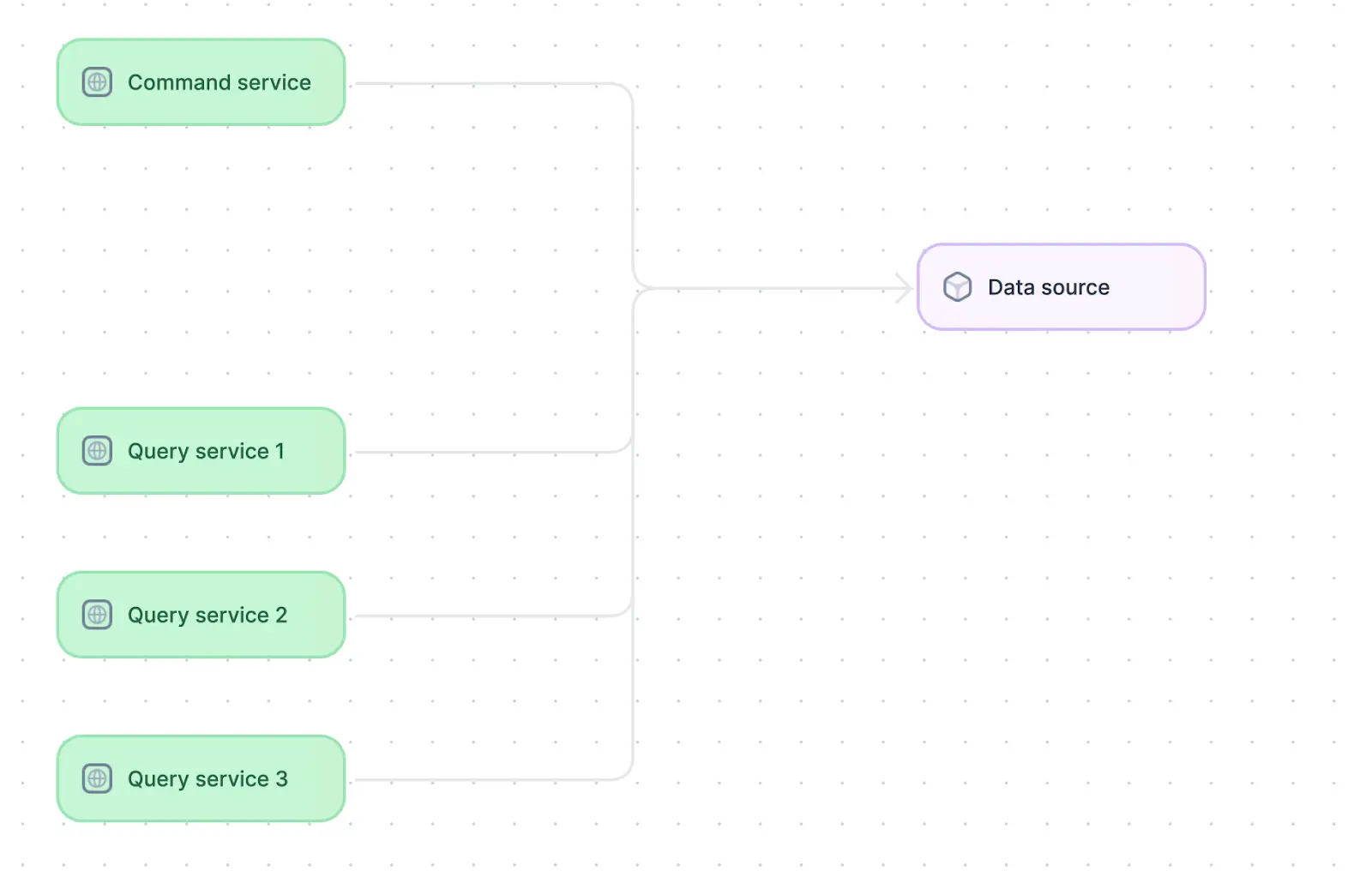
The CQRS design pattern common in distributed systems.
Full-stack session recording
Learn more





The CQRS pattern involves developing one service to read from a given data source and a different service to write to it. This allows reading and writing services to scale independently, enabling each operation to be performed–and the corresponding resources to be scaled–more efficiently. CQRS is a useful pattern in distributed systems with significantly different read and write characteristics for their data. For example, e-commerce websites experience many more reads than writes for products displayed. If the same service were responsible for querying products and adding new listings, it would have to scale up to handle all the read requests while maintaining a lot of idle capacity intended for writes.
Event sourcing


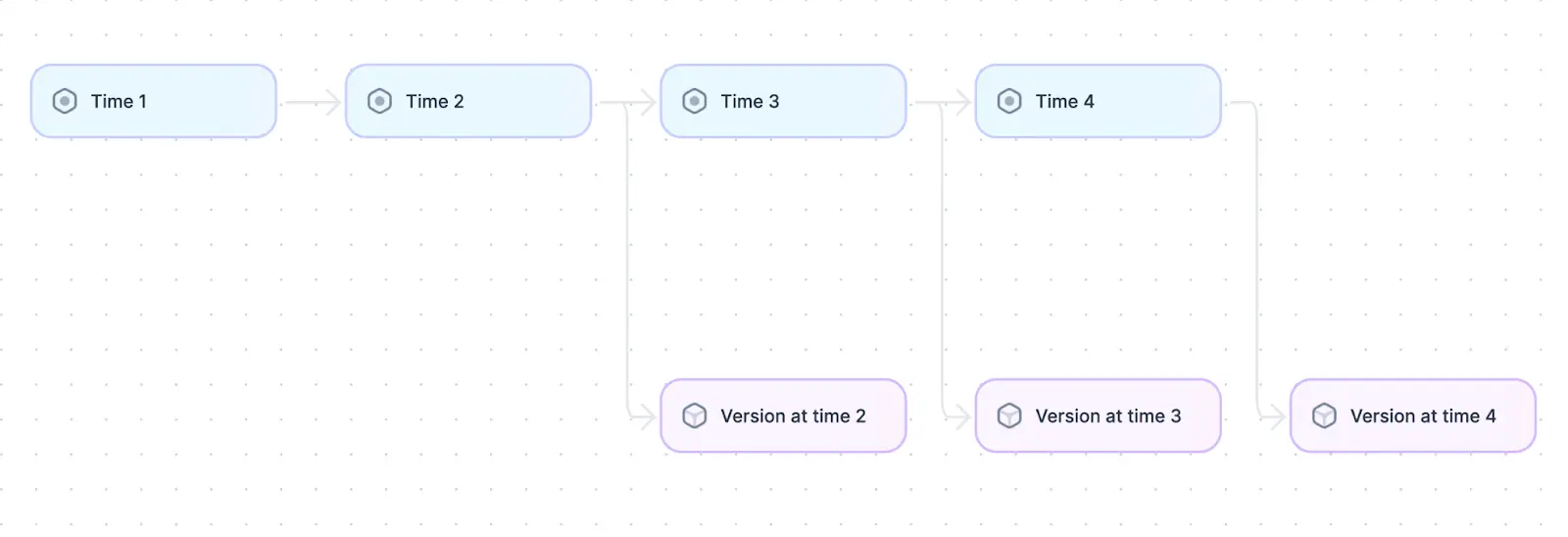
The event sourcing design pattern common in distributed systems.
The event sourcing pattern involves storing changes to data in incremental events over time rather than having a single record and modifying it. Whenever a query is made for a particular record, the underlying system returns the cumulative record after implicitly replaying all the stored events chronologically. This gives the system the ability to recreate the state of the record at any point in its history by replaying events only up to that point.
Event sourcing is useful in systems that need to maintain a comprehensive history of their data, such as version control systems. It is also useful in systems where data is intrinsically in the form of events and users require the ability to extract the cumulative picture from these events. An example of such a system is an event log like Kafka.
Leader election


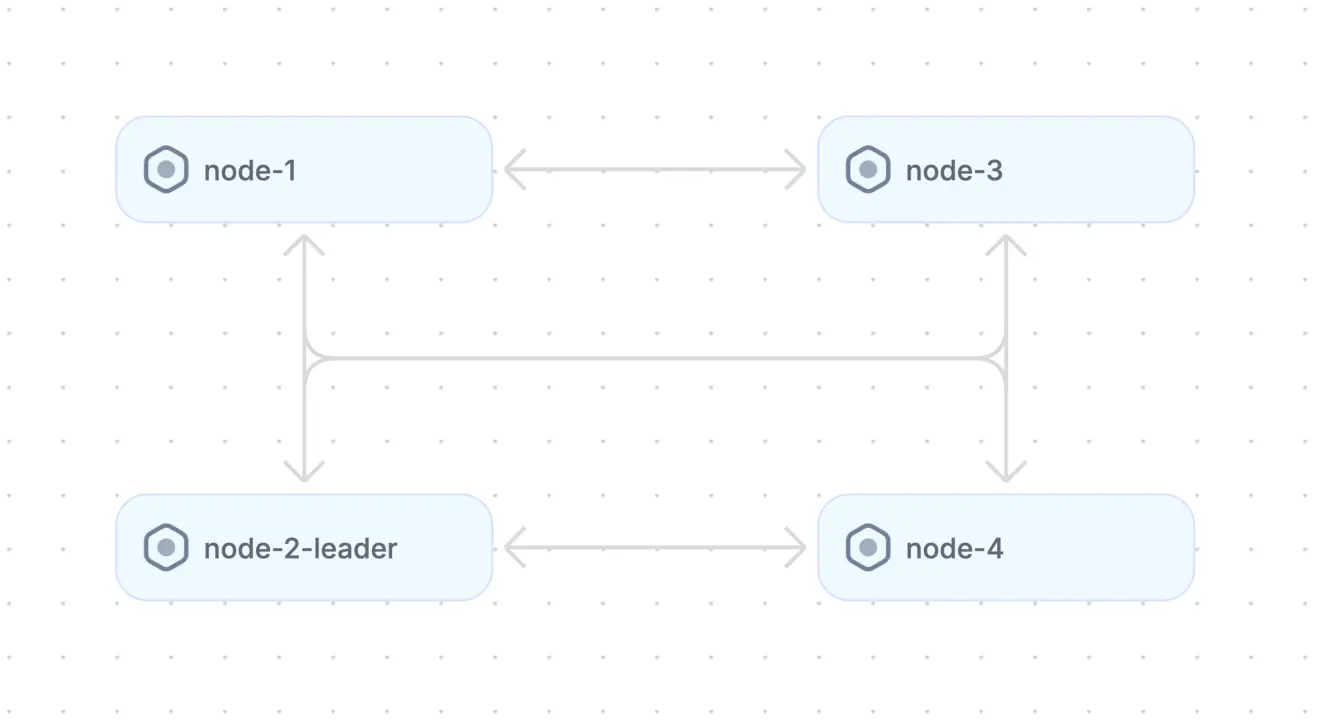
The leader election design pattern common in distributed systems.
Leader election is a pattern that is becoming increasingly common in distributed systems. This is largely because of cloud resources' autoscaling capabilities. As services encounter increasing load, they automatically scale up by adding clones of themselves.
In some situations, however, it is not enough to have multiple identical nodes performing the same tasks; some coordination is also required. Leader election is a pattern by which identical nodes select a leader from among themselves to perform these coordination tasks without conflicts. Since all nodes are otherwise identical, the leadership position is not special or unique; if the current leader experiences a failure or disconnection, a new leader is elected using the same leader election mechanism.
Many distributed systems with identical nodes use variations of the leader election pattern. Some common examples are distributed event logs like Kafka and distributed databases like Cassandra.
Publisher/subscriber


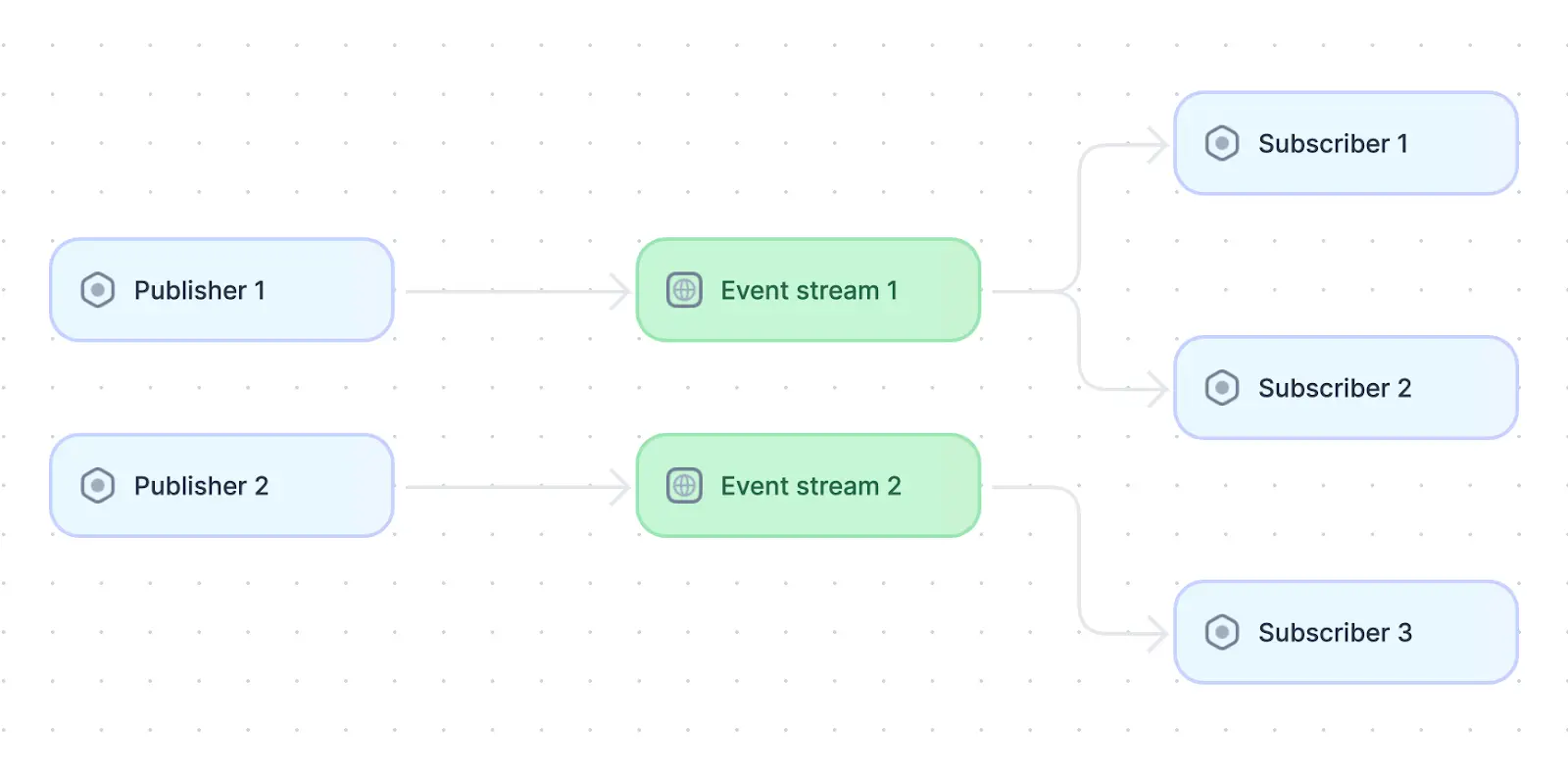
The publisher/subscriber design pattern common in distributed systems.
Publisher/subscriber (or pub/sub) is a pattern whereby the services that produce events are decoupled from the services that consume them. This is done by adding an independent event bus service that has the ability to deliver specific events to other services in the system. Subscriber services listen to events that are relevant to them without being concerned with which service is creating the event, and publisher services push events to the event bus without any awareness of which service may have subscribed to them. As long as the publisher and subscriber use a consistent event interface, communication is unaffected by this lack of awareness.
Pub/sub patterns are very useful in situations where multiple services may need to react to the same event, such as pushing changes from the same logical entity into multiple physical databases. The event bus can easily broadcast the same event to multiple consumers rather than forcing the source service to send the same event to each of them individually. Examples of applications that can act as event buses are message queues like RabbitMQ and event logs like Kafka.
Sharding


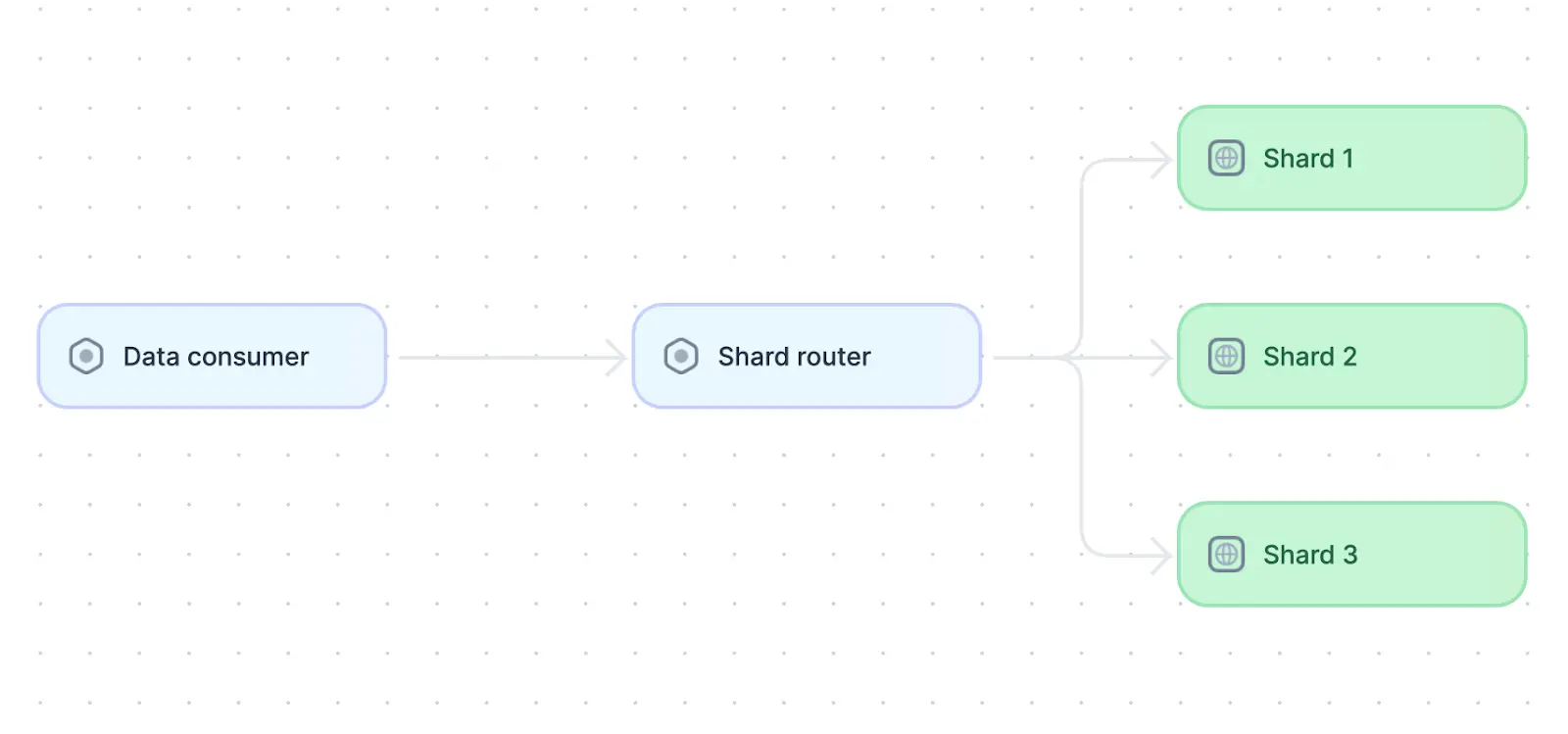
The sharding design pattern common in distributed systems.
Interact with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
Sharding is a pattern used to extend the benefits of distributed systems to data and computation. With this distributed systems design pattern, data from a single database or table is logically divided into shards that can be stored on separate nodes in the system. Data within the same shard is related in some meaningful way so that a single shard can handle queries about similar data. This improves query efficiency and performance. Four standard sharding techniques include:
- Range-based sharding: partitioning data based on a specific range of values, such as customers’ last names.
- Hash-based sharding: partitioning data using a hash function to produce a shard key and distribute data evenly across multiple database shards.
- Directory-based sharding: using a lookup table or central directory to match each record’s database key to its corresponding shard.
- Geo-based sharding: partitioning data based on the geographic location from which the data is expected to be accessed.
While proper sharding improves database response time and scalability, it also adds an additional step to database queries; before accessing the requested data, each query will first need to be directed to the correct shard. Therefore, it is essential that the shard in which each database record is stored can be calculated quickly to ensure overall performance is not negatively impacted.
Sharding is commonly used in distributed databases like Cassandra. It helps scale both relational and nonrelational databases and is used to ensure that databases do not become a performance bottleneck within distributed systems.
Distributed systems design best practices
The final design of a distributed system will likely utilize multiple distributed systems design patterns. After identifying the combination of design patterns that work best for a given system, following best practices for designing distributed systems helps keep the system maintainable and efficient. Some key best practices for designing distributed systems are summarized in the table below.
| Best practice | Description |
|---|---|
| Include some “upfront” system design | Strike a balance between an iterative and upfront approach to system design. |
| Design services based on functionality | Clearly defined responsibilities for each service in a distributed system will make the system more maintainable in the long run. |
| Define clear interfaces | Inter-service communication is a critical part of a distributed system. Separate, clearly defined interfaces that remain as fixed as possible are essential when updating services. |
| Choose the right communication protocols | Communication protocols are critical to inter-service communication. REST is a common and effective protocol for outward-facing communication, while RPC can lead to better internal system performance. |
| Design secure services | Distributed systems have a larger attack surface because all communication between services happens over a network. Use secure channels, keep data encrypted, and be aware of regional compliance regulations like GDPR. |
| Monitoring | Since distributed systems lack a centralized control source, service failures can be hard to detect and can propagate through the system. Build monitoring frameworks to track service health and ensure that failures are contained and fixed early. |
| Maintain thorough and up-to-date documentation | As the system evolves, it is important to track the design of each component and the overall system with up-to-date documentation. Tools like Multiplayer can help streamline and automate this process. |
Include upfront design
In the initial stages of designing a distributed system, it is important to decide how much of the system to design before beginning to build it. Earlier approaches to system design took a Big Design Up Front approach–i.e., designing and perfecting the entire system before implementing it in code. However, modern software systems, by their very nature, are constantly changing and evolving. The requirements of virtually all software systems change as developers learn how the software is being used, collect feedback and/or user analytics, change or upgrade dependencies, and plan for new features. Therefore, spending too much time on designing such a system upfront can be counterproductive and lead to more costly rework when teams implement changes that were not planned initially.
However, inadequate planning of a complex distributed architecture leads to chaotic implementation, a poor understanding of the system’s functional and non-functional requirements, and inconsistencies in the interfaces and expectations between services built by different teams.
Therefore, it is essential to spend some time designing the system upfront. Keep the following recommendations in mind:
- Take an agile approach to system design. Upfront design should not be too detailed or rigid; it should be able to evolve as system requirements change.
- Do “just enough” for your use case. There is no single answer to how much design is sufficient for a distributed system. Architects should analyze their specific system requirements, design accordingly, and reevaluate designs regularly as the system evolves.
- Empower those closest to the work to make design decisions. Design decisions should be made by (or in close collaboration with) individuals who have a direct hand in building the system.
- Use visualizations to drive shared understanding. In general, the system design should be specific enough to be represented through clear and unambiguous diagrams.
- Leverage tools that make documentation accurate and effective. Tools like Multiplayer automate the creation and maintenance of design diagrams to ensure that diagrams remain aligned with the actual service implementation.
Design services based on functionality
A distributed system is more than the sum of its parts, and its overall functioning is purely dependent on the cohesiveness and maintainability of its components. To this end, it is essential to have clear definitions of each service’s responsibilities within the system and to ensure that each continues to fulfill those responsibilities over time.
When designing services, consider the recommendations below.
Make service responsibilities clear and explicit
Each service should perform a distinct logical role within the distributed system and be named declaratively.
Make services as autonomous as is practical
Each service should be strictly responsible for all aspects of its role in the system. This may include exclusive access to the corresponding tables in the database for some applications.
Embrace modularity
If evolving requirements could cause a service to grow and become unwieldy, keep the system modular by adding additional services. Distributed systems are designed to avoid the issues caused by monolithic systems; an overloaded service can become a miniature monolith itself.
Maintain service boundaries as the system evolves
Ensure that each service only adds logical responsibilities that are directly aligned with its role in the system. Services should not enter into the area of ownership of a different service, as this can lead to confusion about each service’s role and make debugging extremely difficult.
For example, consider designing a distributed system for a banking system. The system could have a “user” service responsible for creating, changing, and validating users and an “account” service responsible for creating and deleting accounts. If the account service discovers while creating an account that it is being created for a user that does not exist yet, it should request the user service to create the corresponding user first. If the account service were designed to bypass the user service and instead create the user itself, this could lead to issues and inconsistencies if changes were made in how the user service creates users and stores database records down the line.
Design clear interfaces
When each service has unique responsibilities, inter-service communication is required. When facilitating this communication, it is essential to separate communication interfaces from the actual implementation of individual services. This helps avoid communication problems when making changes to a service. If updates to a service were to change its communication interface, each dependent service would also need to be updated simultaneously.
One click. Full-stack visibility. All the data you need correlated in one session
RECORD A SESSION FOR FREEBecause of this, it is important to have well-defined, stable (rarely changing) interfaces for every service. Here are a few recommendations:
- Build interfaces first. Design and implement service interfaces before designing the actual services.
- Err on the side of reducing changes to interfaces. Spend time upfront to iron out all functionality required for a given service and design its interface as completely as possible. Remember that each change to the interface will likely impact multiple other services.
- Decouple the interface and service lifecycles. Use language constructs like Java and Golang interfaces to give the communication interface a separate lifecycle unaffected by changes to the service implementation. This helps development teams responsible for a given service make changes without worrying about affecting upstream services.
- Make changes backward compatible when possible. If an interface needs to change, keep the change backward-compatible as much as possible by using default values for new parameters; this helps gradually propagate the changes through the system.
In our banking example above, consider the case in which the user service’s createUser API suddenly requires a new parameter containing the user's address. The address parameter will be required every time createUser is called. If the account service does not have access to the user’s address when making calls to createUser, this change to the user service could necessitate a major redesign in the createAccount API. This would then lead to further changes in other services consuming the createAccount API and propagating through the entire system.
Choose the right communication protocol
In addition to interfaces, communication protocols are critical to inter-service communication. Communication protocols are impacted by the type of communication network the application is deployed in, the application’s functional and non-functional requirements, and the nature of the communication that is needed. Two commonly used communication protocols today are REST APIs and RPC. Although both REST APIs and RPC communicate over HTTP (albeit different versions), there are important differences between the two protocols.
REST APIs have been widely used since the early 2000s and have significant library support and online documentation. They are flexible, scalable, faster, and easier to build than gRPC systems. They are best suited for handling smaller data in the form of strings or numbers.
RPC is more performant but somewhat rigid. It is suited for internal service-to-service communication and long-running, bidirectional communication streams, such as those needed to handle larger data like audio and video. Its support for parallel downloads also makes it useful when communication speed is essential, such as in real-time IoT environments.
Other common communication protocols include MQTT, WebSockets, FTP, SOAP, and more. Each can serve different purposes within a distributed system, so it is important to evaluate your application�’s needs carefully before choosing the appropriate protocols.
Design secure services
Security is another important factor to consider while designing a distributed system. Because such systems are distributed across many nodes, communication must occur over external networks, and each communication channel becomes an attack surface for threat actors. Therefore, it is essential that security is factored into the design of each service and the system as a whole.
Here are some points to consider:
- Encrypt data. Ensure that all data is secured and encrypted, whether at rest (stored in a database) or in transit ( communicated over a network). For example, use secure communication channels (such as HTTPS instead of HTTP).
- Authenticate and authorize every service. All data transferred between services should be authenticated and authorized by the receiver.
- Limit the transmission of sensitive data. Be aware of which data is being sent between services. Services should only send the minimum required data over the network.
- Consider compliance. If the system is spread over a large geographical area, governance and compliance factors may also come into play. For example, services should not send personally identifiable information (PII) outside its governance boundary.
Monitor service health
Another consideration when designing distributed systems is that each service can individually get into an error state or crash, and there is often no mechanism for other services to detect this immediately. To mitigate this risk, it is essential to have robust monitoring systems in place to detect when services fail and handle the resultant issues.
Use this distributed systems monitoring checklist to help determine whether there is sufficient monitoring in place:
- A robust health monitoring system is in place that periodically checks the health of all essential services.
- An automated mitigation process is in place for each service to avoid failures propagating to other services. Use design patterns like the circuit breaker pattern to achieve this.
- Operations teams are automatically notified of failures so that they can be fixed quickly and downtime can be minimized.
- Each service has thorough logging in place to help debug and repair failures.
- Each service has built-in high availability and scaling capabilities to avoid repeated failures.
Once monitoring is in place, you can use other tools to investigate failures and improve your system to prevent issues proactively. Start by integrating observability platforms like OpenTelemetry into your system to standardize the way you collect traces, metrics, and logs across distributed services.
Once proper instrumentation is in place, you can export this data to advanced platforms that correlate backend events with frontend behavior and allow developers to truly follow a request as it moves through the system. For example, Multiplayer full stack session recordings capture frontend interactions together with the corresponding API calls, background jobs, and service communications to provide a synchronized, end-to-end view of how the system behaves in production.


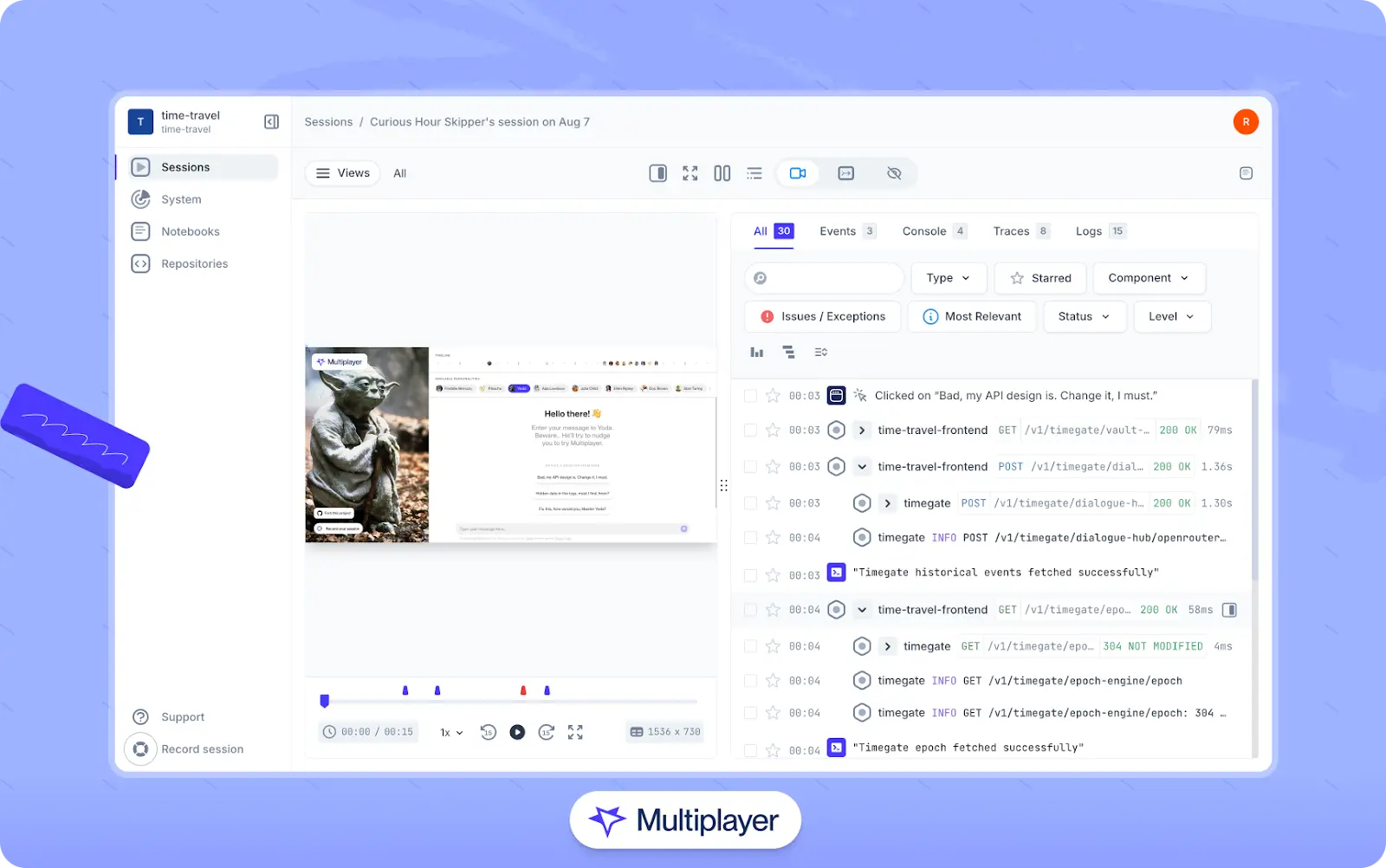
Multiplayer full stack session recordings
Session recording data can also be exported via Multiplayer’s MCP server to provide AI coding assistants with the context they need to analyze your system, improve code suggestions, and make recommendations based on real runtime behavior.
Maintain thorough and up-to-date documentation
Although documenting system design during the upfront design phase is essential, documentation efforts should not stop there. Documentation should be kept up-to-date as different services are implemented and the overall design evolves.
Different types of architecture diagrams can help document the logical flow of data through the system and how the system behaves in different scenarios. The internal structure, behavior and data flow of each service should also be documented to help development teams understand the expectations from the service over time. Service interfaces should also be thoroughly documented and maintained so that other services can effectively communicate with a given service.
One effective way to document, centralize, and validate a variety of system interactions and development decisions is through interactive notebooks that combine narrative text with executable code and API calls. Instead of maintaining static documentation that can quickly become outdated, teams can use notebooks to record architectural decisions, experiment with configurations, and validate runtime behavior directly against the live system. For example, a notebook might include sample API calls, schema validations, infrastructure queries, or automated assertions that confirm expected outcomes.

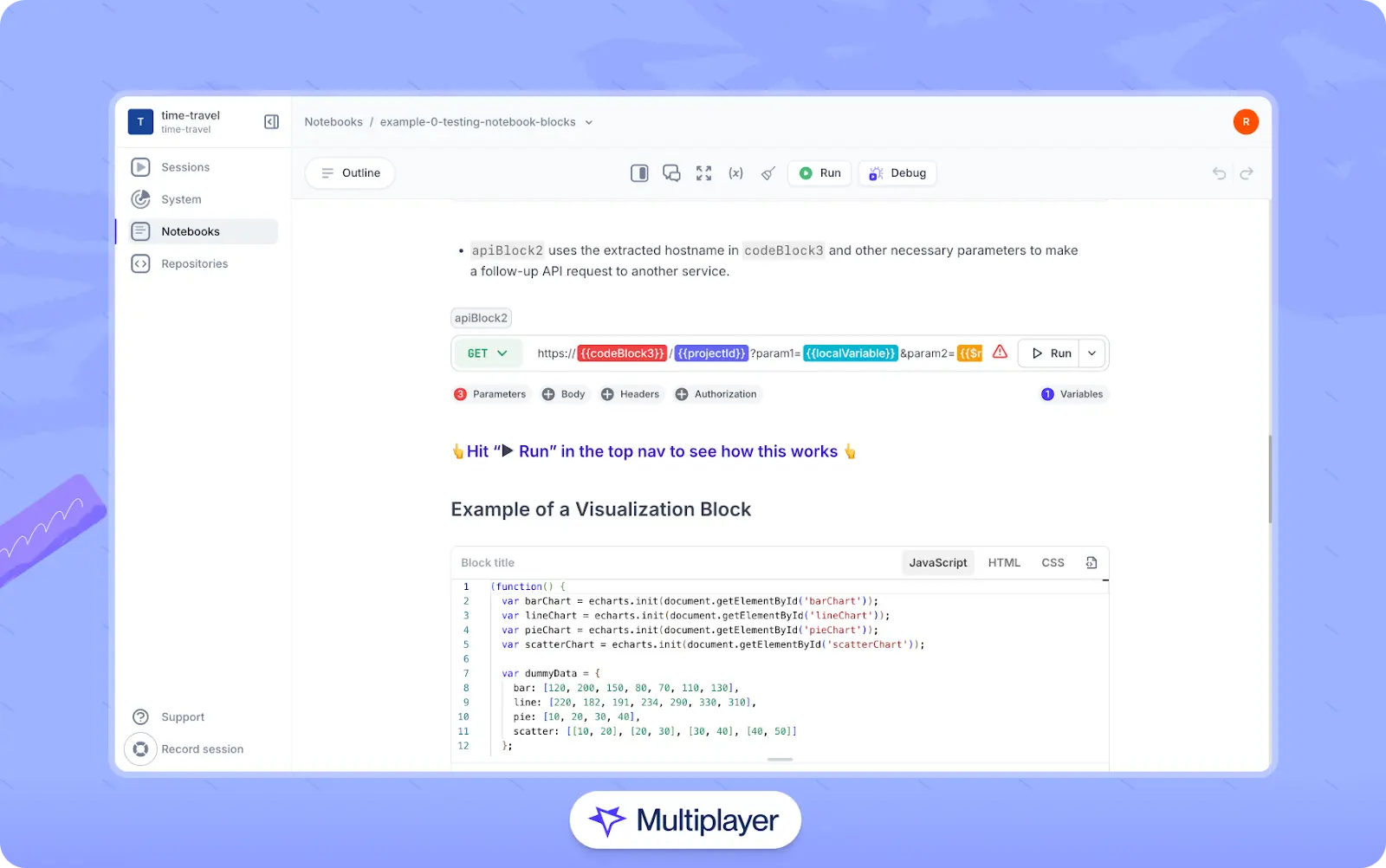
Multiplayer notebooks
Notebooks can be created manually, but to ease the burden on developers, they can also be generated from natural language using AI assistance or created automatically from a full stack session recording.
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREELast thoughts
A software system designed as a distributed set of independent services has powerful abilities to scale and handle large and varying loads. However, such a system can also lead to overwhelming complexity if not designed well. Architects responsible for distributed systems design should employ common design patterns where applicable. In addition, they should ensure that other best practices are built into the overall system design as well as the design of each service. In these ways, system architects can design efficient and performant distributed systems capable of meeting modern applications' demands.