Guide
Code Refactoring: Best Practices & Examples
Table of Contents
Code refactoring modifies existing code's structure, design, and readability without altering its external behavior or functionality. It may involve abstracting or simplifying code to make it easier to maintain, optimizing code for improved performance, removing redundant code, or even changing application architecture. While code refactoring is critical for long-term software system health, many teams struggle with refactoring due to time constraints or suboptimal development practices.
This article explores proven strategies for overcoming these challenges and realizing the benefits of code refactoring. We will provide actionable insights to guide your organization's refactoring efforts while minimizing risks and adhering to best practices.
Summary of code refactoring best practices
The table below summarizes the six code refactoring best practices we will explore in this article.
| Best practice | Description |
|---|---|
| Determine what code to refactor | Identify refactoring opportunities using key indicators such as code smells, performance bottlenecks, recurring bugs, challenges in adding new features, and feedback from reviews or development tools |
| Perform code refactoring incrementally | Incremental refactoring reduces risk and complexity, integrates well with agile workflows, and balances tech debt management with feature delivery. |
| Consider architectural refactoring | Architectural refactoring involves overhauling a system's structure to address core issues like scalability, maintainability, or outdated technologies. |
| Write automated tests to refactor safely | Automated tests, including unit, integration, and regression tests, validate code behavior and ensure safe refactoring. Test-driven development (TDD) enhances this process by defining requirements upfront and providing immediate feedback on changes. |
| Communicate major changes throughout your organization | Communicate significant refactoring decisions through design documents and reviews to ensure alignment, minimize risks, and enable necessary team updates. |
| Leverage existing tools for effective refactoring | Leveraging tools like static analysis and architectural visualization platforms simplifies refactoring by automating tasks, identifying refactoring opportunities, and providing high-level system insights. |
Determine what code to refactor
Identifying code that could be refactored is often trivial. Many different components of the system can enjoy the benefits of code refactoring. However, while it can be tempting to perform large-scale overhauls of a codebase, the realities of development timelines require teams to prioritize refactoring efforts. In this section, we present common “symptoms” of code that should be refactored and how to address these issues.
Code smells
Code smells are indicators within a codebase that suggest potential problems in design, structure, or implementation. While code smells do not mean the code is broken or non-functional, they highlight areas that are difficult to maintain, understand, or extend. If left unaddressed, these issues often lead to technical debt.
Martin Fowler popularized the term "code smell" in his book Refactoring: Improving the Design of Existing Code. Code smells often signal deeper issues that can degrade code quality over time.
Let’s look at some common code smells.
Duplicated code
Duplicated code is the repetition of the same code logic across multiple places. Duplicated code increases maintenance overhead because any change must be replicated everywhere.
Here’s an example of duplicated code:
def calculate_discount(price, discount_rate):
return price * (1 - discount_rate)
def compute_final_price(price, discount_rate):
return price - (price * discount_rate)Although these two functions appear different on the surface, they calculate the same value using slightly different approaches. Refactor this by consolidating them into one function. For example:
def calculate_final_price(price, discount_rate):
return price * (1 - discount_rate)By making this small change, we avoid redundant logic, improve consistency across the codebase, and simplify future maintenance.
Large classes or methods
When methods or functions try to do too much, they violate the Single Responsibility Principle (SRP). These methods are difficult to read, test, and debug. The SRP is one of the SOLID principles of object-oriented design. A class, module, or function should focus on a single, well-defined responsibility or task.
Tight coupling
Tight coupling occurs when components are overly dependent on one another, making changes difficult. Refactor by introducing interfaces or using dependency injection. For example:
# Tight coupling example
class ReportGenerator:
def __init__(self):
self.database = Database()
# Refactored to reduce coupling
class ReportGenerator:
def __init__(self, database):
self.database = databasePassing the database instance to ReportGenerator through the constructor (dependency injection) allows ReportGenerator to accept different database implementations (e.g., a mock database for testing or a production database for deployment) without altering its code.
Deep nesting and complex logic
Nested logic can make code hard to read and maintain. Flatten nested structures and extract methods to improve clarity:
if user:
if user.is_active:
if user.has_permission:
perform_action()For improved readability, this code can be refactored to:
if user and user.is_active and user.has_permission:
perform_action()Outdated dependencies
Dependencies that are no longer maintained or supported can create security risks and hinder development. Regularly audit your dependencies and update to actively supported versions. Use tools like npm-outdated or pip list --outdated to identify outdated packages.
Performance and scalability bottlenecks
Performance bottlenecks are specific areas of code or processes that slow down execution and significantly impact application speed and responsiveness. Common causes of performance bottlenecks include inefficient algorithms or data structures, repeated database queries, excessive I/O operations, and unoptimized loops or nested logic.
Scalability bottlenecks are system limitations that prevent the application from handling increased load or user requests. Scalability issues arise from limited server resources, poorly distributed workloads, and inefficient caching strategies.
Both performance and scalability bottlenecks can significantly hinder application efficiency, user experience, and system growth. Identifying and addressing these issues helps your application’s responsiveness and scalability. This process requires profiling tools, monitoring, and optimization strategies.
How to address bottlenecks
To resolve performance and scalability bottlenecks effectively, follow a structured approach that identifies, prioritizes, and optimizes problematic areas in the codebase.
The first step is pinpointing which areas of your code base are causing bottlenecks. Use profiling tools to help uncover which code sections consume too many resources or take too long to execute. Once you have identified the bottlenecks, prioritize them according to their impact on overall performance.
Performance and scalability issues are highly context dependent, and there is no one-size-fits-all approach to address them. However, several proven methods may help improve your application’s resource consumption, execution time, and ability to function well under high load:
- Replace inefficient algorithms, like those with O(n²) complexity
- Implement caching to cut down on execution time for large datasets
- Improve database queries by using indexes or improving JOIN queries.
- Reduce latency through the use of CDNs or distributed databases
- Use data compression techniques to reduce the amount of data transferred over the network
- Optimize thread pools, connection pools, and buffer sizes to better handle concurrency and prevent bottlenecks
- Include rate limiting and throttling in your APIs to prevent abuse and ensure fair usage
- Implement load balancing and auto-scaling to distribute load across multiple servers and dynamically adjust the number of servers based on traffic demands
Full-stack session recording
Learn more





Performance and scalability issues also often arise due to inefficient database design or access patterns. Consider implementing techniques such as sharding, partitioning, and data replication to address read-heavy workloads. Teams can handle flexible schema requirements with NoSQL databases or schema evolution strategies to accommodate changing data structures.
Frequent bugs
Repeated fixes in the same area often signal a need for refactoring. When developers consistently encounter issues in a particular module, method, or class, it typically indicates deeper structural issues in the codebase. For example, the code may be overly complex, poorly structured, or lack proper error handling. Teams should use code refactoring to address these issues, improve stability, and reduce recurring problems.
The first step is to identify the source of the frequent bugs. Tools like git blame, git log, or SonarQube (an open-source platform that helps developers analyze and improve the quality of their code) can help you identify which files need frequent changes and fixes. In addition, advanced tools like Multiplayer’s full stack session recordings can help pinpoint the source of bugs in the context of the overall software system by providing recorded sessions of all relevant session data, from frontend screens to deep platform traces, metrics, and logs.
Once you have a general idea of which files, functions, or services are to blame, dive deeper. Rather than quick patches, take the time to investigate the root cause and take the necessary action to fix it. This may involve measures like improving a function, combining functions, rewriting convoluted code, or improving badly performing database queries that might timeout to failure. AI assistants can also help in this process, and they are particularly useful when they are provided with system context from full-stack session recordings.
Properly remediating bugs can take time but yields significant benefits in the application’s long-term health. With this in mind, managers should be sure to allocate adequate time in sprint planning for developers to address bugs in a way that contributes to the overall maintainability of the codebase.
Difficulty onboarding new developers
Difficult-to-understand code creates barriers for new developers joining the team. Slow or inefficient onboarding affects productivity, leads to frustration, and delays feature delivery. Refactoring for clarity helps new developers and benefits the entire development team.
If new hires regularly complain about their onboarding experience, listen to them. Fresh perspectives often highlight issues that current developers have grown accustomed to. New hires usually come from competing companies with different development practices, and their insights could help you continually improve your organization’s development approach.
Perform code refactoring incrementally
Large-scale refactoring projects can introduce risks, including merge conflicts and system-wide disruptions. Incremental refactoring mitigates these challenges by keeping changes small, manageable, and testable.
To implement incremental refactoring effectively, you can follow some general rules. The Boy Scout Rule (“Always leave the code better than you found it”) is highly applicable to code refactoring. In practice, following the Boy Scout Rule means making small improvements to the codebase whenever possible as teams modify existing code. Examples include removing unused imports, refactoring duplicate or redundant code, and renaming variables for clarity. For example:
# Before refactoring
def calc(a, b):
res = a + b
return res
# After refactoring
def calculate_sum(num1, num2):
return num1 + num2Another practice that is easy to implement is automating code-style checks. If you already use a modern IDE, add tools like Prettier or ESLint to enforce coding standards during pull requests.
These small changes, when made consistently, lead to significant long-term improvements.
Consider architectural refactoring
Architectural refactoring becomes necessary when code-level changes are insufficient to meet performance, scalability, or maintainability goals. It involves redesigning the system’s structure to address fundamental issues.
Consider an architectural refactor when the problems you are facing are systemic or when the application has accrued significant architectural technical debt. For instance, if your application struggles to handle significantly increased traffic, minor optimizations to individual functions are unlikely to fix the issue. Instead, you may need to consider more substantial changes, such as moving from a monolithic architecture to microservices, implementing caching layers, or adopting horizontal scaling. Such major changes are not at the code level; they are fundamental alterations to your system design.


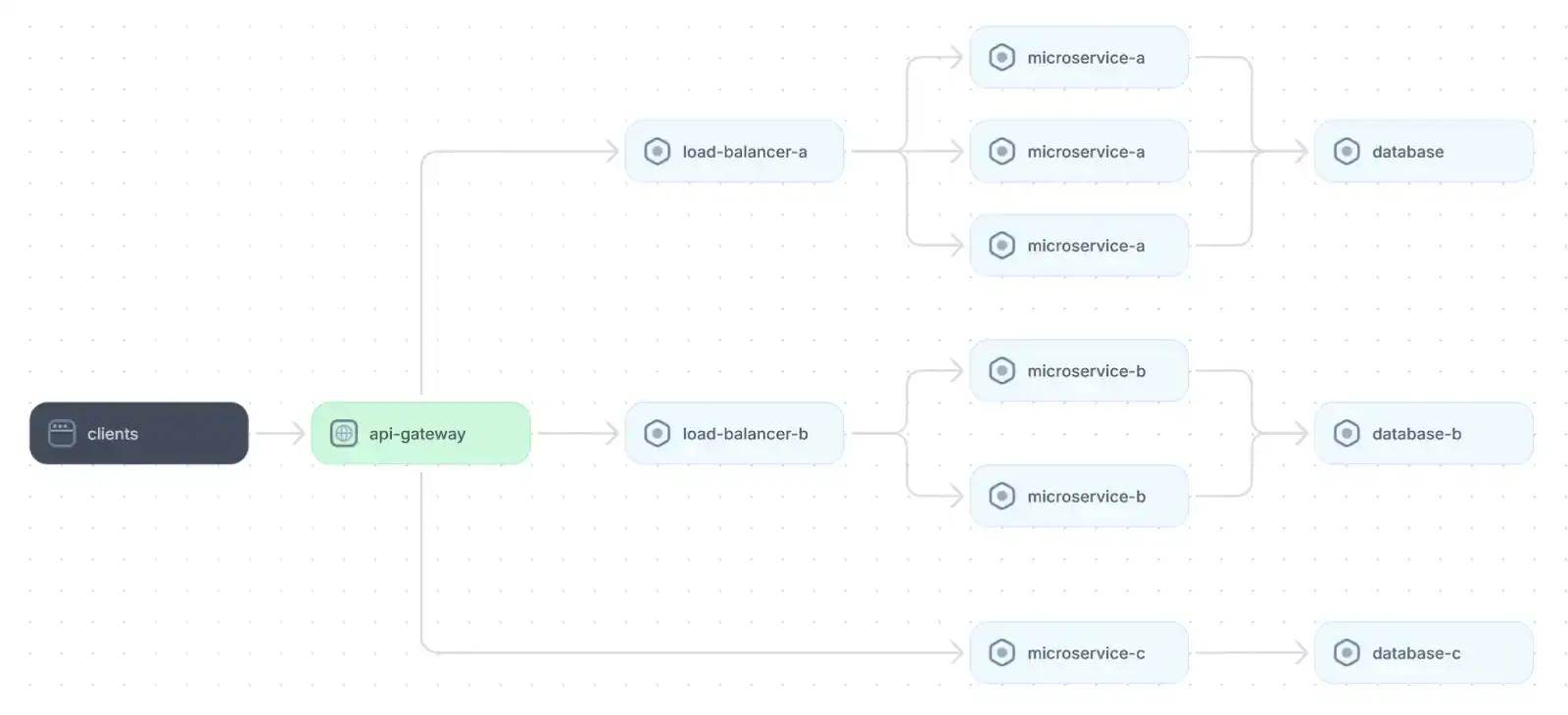
An example of microservices web application architecture
One of the biggest challenges in architectural refactoring is leveraging a comprehensive understanding of your existing system to identify which changes are needed. The sprawling, complex nature of modern distributed systems makes them difficult for any individual to grasp, especially when the system is not adequately documented.
Before embarking on any sort of larger architectural effort, be sure that developers and other stakeholders have a clear understanding of what is already in place so that decisions are driven by data rather than guesswork or assumptions. Tools like Multiplayer can help in this process. Its system dashboard automatically discovers and documents services, APIs, and dependencies, and its full stack session recordings capture end-to-end recordings of system behavior so that developers can see how requests flow through the live environment.
Interact with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
Write automated tests to refactor safely
Refactoring code without proper testing is risky because even small changes can unintentionally break existing functionality. Automated tests provide a critical safety net during refactoring, ensuring that the system behaves as expected both before and after the changes.
Types of tests
To refactor safely, a comprehensive suite of tests that target different aspects of the system is necessary. Though each type of test serves a different purpose, they collectively help ensure code stability. Let’s examine the three most common types of functional tests.
Unit tests
Unit tests focus on testing individual functions, methods, or classes in isolation. They are designed to validate the smallest building blocks of a system without dependencies on other components. Unit tests are typically fast to execute and provide targeted feedback on specific functionality.
For example, the code below tests a simple add function:
# Unit test for the add function
def test_add():
assert add(2, 3) == 5
# Function implementation
def add(a, b):
return a + bUnit tests ensure that a function produces the correct result for given inputs, making it easier to catch bugs during refactoring.
Integration tests
Integration tests validate that multiple components of the system work together as expected. Unlike unit tests, integration tests ensure that interactions between modules, services, or external systems function correctly. These tests are particularly useful for verifying database queries, APIs, or service-to-service communication.
For example, the following test verifies the integration between a web API and a database:
# Integration test example
def test_fetch_user(db_connection):
db_connection.insert_user(1, "Alice")
response = api.get_user(1)
assert response['name'] == "Alice"When refactoring, integration tests help ensure that modifications to one part of the system do not break its interactions with other components.
End-to-end tests
End-to-end (E2E) tests simulate real-world workflows and ensure that the entire application works correctly from start to finish. These tests are broader in scope and focus on validating complete user interactions, such as submitting a form or completing a checkout process. While E2E tests can be slower to run, they provide confidence that the system functions as expected from a user’s perspective.
Unit, integration, and E2E tests can be combined to form a regression test suite. The goal of a regression test suite is to verify that previously fixed bugs remain fixed and that new changes to a system do not reintroduce those issues. In the context of refactoring, regression tests act as a safety net by ensuring that functionality stays intact.
Test-driven development
Test-driven development (TDD) is a methodology where developers write tests before writing the corresponding implementation code. In TDD, you write tests first to define what your code should do, then write just enough code to make that test pass. As long as tests are well-designed, you can refactor your implementation confidently knowing the tests will catch any mistakes.


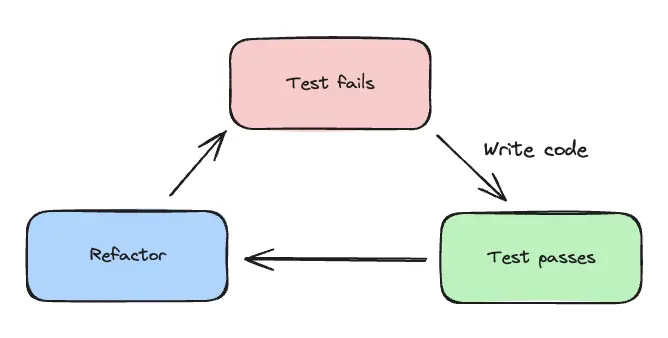
The test-driven development cycle (adapted from source)
As shown in the graphic above, the cycle that developers follow with TDD is:
- Write a failing test (red).
- Implement code to pass the test (green).
- Refactor while keeping the test green.
One click. Full-stack visibility. All the data you need correlated in one session
RECORD A SESSION FOR FREEWhile TDD requires an initial time investment, it can lead to improved code quality, a more thorough understanding of functional requirements, and increased confidence in the software. In practice, we recommend adopting a hybrid approach. Utilize TDD more extensively in stable, easily testable areas (e.g., unit tests of core business logic). However, in areas that change more frequently or are more time-consuming to test (e.g., frontend UI testing), your team may benefit from a more flexible development approach.
Communicate major changes throughout the organization
Effective communication is crucial during refactoring efforts, especially for major changes that may impact multiple teams, workflows, or systems. Clear communication ensures alignment across stakeholders, minimizes disruptions, and reduces the risk of downstream issues. Let’s look at communication strategies to help maintain transparency throughout the refactoring process.
Documenting decisions
Documenting decisions provides clarity and ensures that everyone understands the "why" behind a given refactoring effort. Documentation serves as a reference point for stakeholders and developers, enabling smoother collaboration and more informed decision-making.
Draft a design document
Before implementing large-scale changes, draft a software design document that clearly outlines the following:
- System architecture changes: Describe modifications to the system's overall structure, including components, interactions, and dependencies.
- UI/UX changes: Outline proposed updates to the user interface and experience to ensure consistency and usability improvements.
- Database or API changes: Specify planned alterations to database schemas or API endpoints to support new features or enhancements.
- Potential risks: Identify potential risks (e.g., downtime, regressions) and how they will be addressed.
- Security considerations: Highlight security measures to protect data, ensure compliance, and mitigate potential vulnerabilities.
- Deployment strategy: Define the approach for releasing changes, including rollout plans, rollback procedures, and testing phases.
For example, if refactoring a monolithic application to a microservices architecture, the design document might include comparing the current state (monolith) and the proposed state (microservices), along with migration phases and a rollback strategy. For more information on creating effective software design documents, check out our free software design document template.
Share and review the design document
Once the design document is drafted, share it with stakeholders–including team leads, developers, QA teams, and product managers–for review and feedback. This step ensures buy-in and provides an opportunity for others to identify overlooked risks or offer suggestions for improvement.
Conduct design review meetings to discuss the document, clarify concerns, and finalize the plan. A collaborative tool like Multiplayer can assist in this process. Instead of working across multiple tools to document different aspects of the system, consider using a tool like Multiplayer Notebooks to provide a centralized space for APIs and instructions, documentation, decision records, and any other documentation you may require.
Document implementation details
During the refactoring process, document specific implementation details to make the changes easier to understand and review. You can use inline comments, commit messages, or version control notes to provide more context as to why you made a specific change or decision. These should be concise but detailed enough to not warrant further questioning from reviewers.
Commit: Refactored order processing logicExample commit message to explain the purpose of refactoring changes.
Communicating with partner teams
For major refactoring, it is often necessary to collaborate with teams beyond the developers directly working on the project.
The number of different teams you communicate with will depend on the size of your organization:
- If your organization has a dedicated QA team, you’ll have to loop them in early, as code refactoring can break existing tests or introduce new scenarios that might not be covered by existing manual or automated tests.
- If your refactor touches on infrastructure, you must coordinate your changes with your DevOps team. They’ll need time to update configurations, adjust CI/CD pipelines, or set up new environments. Sharing infrastructure details early can prevent issues during deployment.
- If your refactor requires documentation or uncovers a product-impacting issue, coordinate with documentation or product teams.
As a general rule, consider the impact your changes might have on your colleagues before refactoring.
Leverage existing tools for effective code refactoring
There are several types of tools designed to provide automated feedback throughout the development process. The primary categories of tools you can integrate into your workflow are:
- Static analysis tools
- Code formatting and linting tools
- IDE feedback
- Security analysis tools
- Visualization tools
Let’s take a closer look at each of these tools and how they can help improve code refactoring processes.
Static analysis tools
Static analysis tools examine code without executing it to identify issues like code smells, syntax errors, or potential bugs. They ensure code quality by catching errors early in the development cycle. Some examples of these tools include SonarQube, ESLint for JavaScript, and Pylint for Python.
IDE feedback and linting tools
IDE feedback and linting tools enforce consistent code style across the team by identifying and fixing formatting issues. They take the guesswork out of code style, automatically formatting everything to a standard that everyone follows. This reduces cognitive load and makes code reviews less about nitpicking styles and more about substance. Some examples include Prettier for JavaScript, Black for Python, and Stylelint for CSS.
Modern IDEs like IntelliJ IDEA, Visual Studio Code, and PyCharm flag issues like unused variables or suggest improvements for performance, such as optimizing loops. For example, PyCharm might point out, “Unused variable 'temp'. Consider removing it,” helping you keep your code lean and efficient.
Security analysis tools
Security analysis tools detect vulnerabilities and highlight insecure code patterns. These tools act as a safety net, helping developers focus on writing effective code while automating the checks that keep it secure, efficient, and consistent. While never a substitute for a dedicated security team, these tools help integrate security into day-to-day development workflows by automatically detecting many common vulnerabilities, insecure code patterns, and configuration issues. Some example tools include SonarQube, Snyk, and Bandit.
Visualization tools
Visualization tools help teams understand and improve their architecture by providing high-level insights into system dependencies and structure. They are especially useful when dealing with large, complex systems where identifying refactoring opportunities can be challenging.
For example, Multiplayer offers a range of features that enable teams to visualize their system, detect inefficiencies, and plan refactoring with confidence. Here’s how you might use Multiplayer to conduct a code refactor:
Gather information with the system dashboard
The system dashboard consolidates insights from across your backend system, enabling you to detect issues or inefficiencies at a glance. Use the system dashboard to ensure you have up-to-date information on all services, APIs, dependencies, etc., and to quickly identify bottlenecks or underperforming components that may need optimization. These insights can help you prioritize refactoring tasks based on system impact. As you refactor, monitor the effects in real time to validate improvements and ensure stability.
Go deeper with full stack session recordings
Rather than trying to reproduce a specific issue based on vague, incomplete reports and searching through a complex web of disparate information (APM data, logs, traces, scattered documentation, etc.), use full stack session recordings to gain a full picture of the bug. Each recording captures the full end-to-end context of a bug, including the precise user actions that triggered it and correlated backend traces, metrics, and logs. Recordings can also be easily shared with team members so that everyone is on the same page.


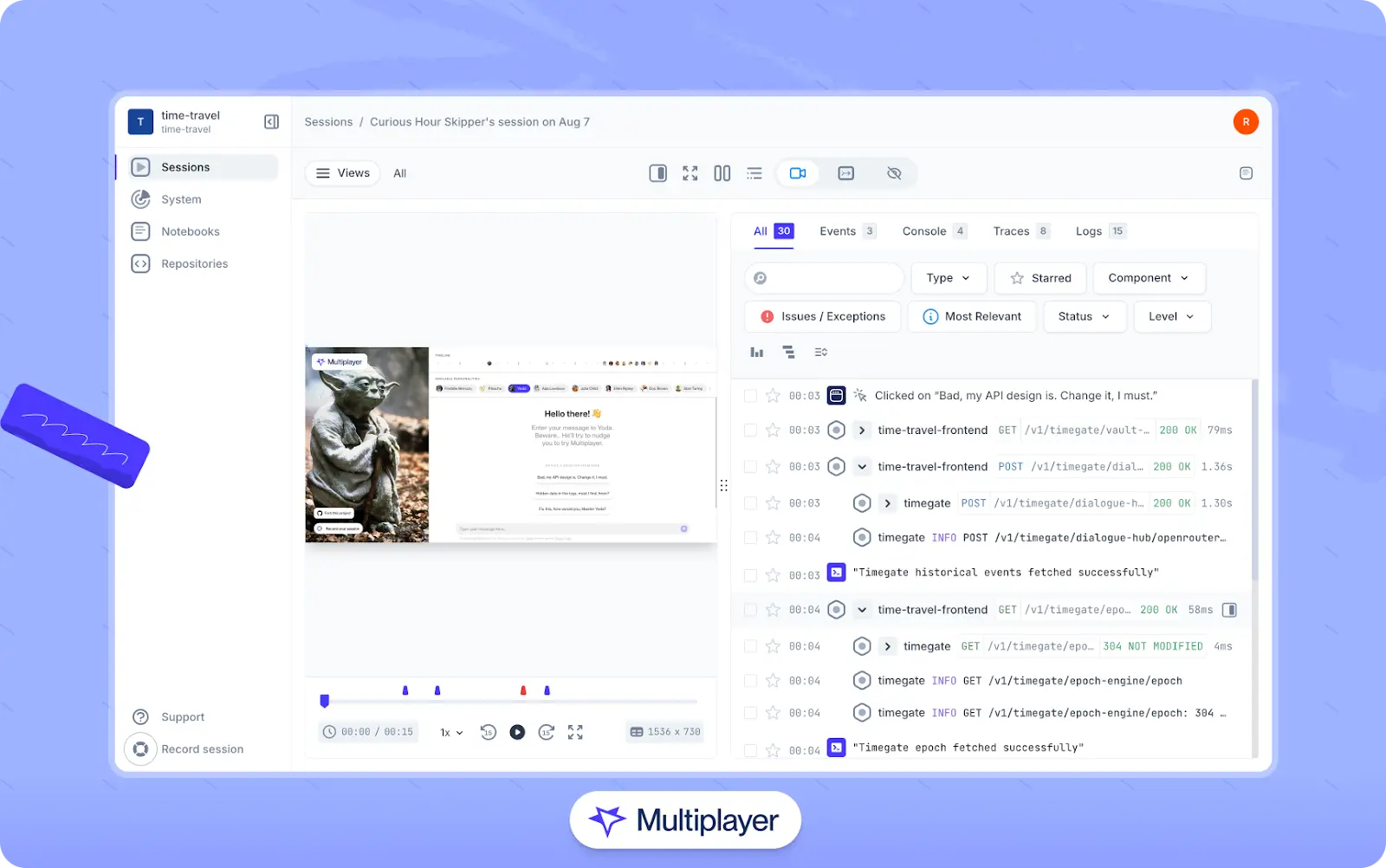
Multiplayer’s full stack session recordings
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREEIntegrate with AI tooling
Once you have gathered contextual data from session recordings, connect this information to copilots and AI IDEs via Multiplayer’s MCP server. Doing so helps AI tools generate better suggestions because they are informed by real runtime behavior rather than static code alone. With this integration, AI tools can:
- Identify inefficient code paths or redundant service calls.
- Generate targeted refactor suggestions grounded in real production behavior.
- Automatically summarize complex dependencies or suggest clearer abstractions.
- Anticipate the downstream impact of proposed changes before they’re implemented.
Document and validate with notebooks
Refactored code must be tested and documented, and this presents a particular challenge in the age of AI tools that produce large quantities of code with inconsistent results. Using Multiplayer, developers can auto-generate a notebook with a runnable test script directly from a full stack session recording. Notebooks allow these scripts to live alongside written documentation (narrative explanations, observations, ADRs, assertions about expected behavior, etc.) so that developers can validate and understand each refactor in the context.
Last thoughts
Code refactoring is a continuous journey toward maintaining software quality and scalability. By following best practices like knowing when to refactor, working incrementally, considering architectural changes, using automated tests, ensuring clear communication, and leveraging tools, you can guide your teams toward more effective and efficient codebases. Prioritize these practices to build resilient systems that stand the test of time.