Guide
API Development: Best Practices & Examples
Table of Contents
APIs are ubiquitous in modern software, whether internal for use within an organization or external to expose data or functionality to third-party users. Understanding how to design and implement efficient, secure APIs is essential for anyone building a web app, creating a mobile service, or integrating third-party tools.
This article delves into the process of creating APIs, including how to design clear interfaces, ensure high performance, and safeguard data with robust security practices. This article covers the best practices for developing APIs and offers practical examples to help readers with implementation.
Summary of API development best practices
The table below summarizes the best practices covered in this article.
| Best practice | Description |
|---|---|
| Prioritize API consumers during the design process | Design APIs with users in mind by prioritizing simplicity and consistency for ease of use, implementing versioning to accommodate future updates smoothly, and providing clear, up-to-date documentation. |
| Choose an appropriate architectural style | API architecture design should be informed by a thorough understanding of different system architectural styles, such as monolithic, microservices, event-driven, serverless, edge computing, and peer-to-peer. |
| Use RESTful or other appropriate paradigms | Choose the right API paradigms for your use case, such as REST for stateless, resource-based interactions; GraphQL for flexible querying; and gRPC for high-performance communication. |
| Handle errors gracefully | Handle errors using standardized HTTP status codes (e.g., 200 for success or 400 for bad requests) and provide clear, user-friendly error messages to help API consumers troubleshoot issues quickly. |
| Design for security | Securing API access involves various strategies, such as using authentication standards like OAuth 2.0 or JWT, separating authentication from authorization, validating inputs to prevent attacks, encrypting communications with HTTPS, implementing rate limiting, and handling CORS to prevent unauthorized access from other domains. |
| Optimize performance | Implement pagination and filtering for large datasets to optimize API performance, and use caching headers like Cache-Control and ETag to reduce server load. Enable Gzip or Brotli compression to minimize data transfer size, and consider asynchronous processing for long-running tasks to improve efficiency. |
| Use open standards and protocols | Adhere to established standards, such as using the JSON format for request and response bodies, tools like JSON Schema to validate data structures, and OpenAPI specifications to describe HTTP APIs. |
| Document using a dedicated tool | Store documentation in a central location using a tool that combines executable API blocks and code snippets with live system context. |
API development methods
Before diving into API development best practices, let’s examine two concepts commonly discussed in API development: “design-first API” and “API-first design.” Despite the similarity of these terms, they reflect entirely separate development methodologies and are used in different contexts.
API-first design
API-first design is an approach to designing a system as a whole. In API-first design, teams prioritize the API as the focal point of the entire system. The API contract is finalized before designing any other part of the system, which means that all stakeholders—such as frontend and backend developers and test engineers —must align on the API’s functionality upfront. The API contract is then treated as the primary interface that all other system components—such as frontends, backends, and integrations—must interact with. The main benefits of this approach are alignment between different teams and more complete documentation, which facilitates parallel development and reduces misunderstandings.
Once the API design is finalized, the following activities can occur simultaneously:
- Backend developers can design the database and services to provide the API's required data.
- Frontend developers can begin implementing user interfaces using mock data that adheres to the API's schema.
- QA teams can create test cases based on the API documentation.
Design-first API
Design-first API refers to how an individual API is developed. In the design-first approach, an individual API’s contract is completed and documented before any code is written. This contrasts with code-first API development, in which developers write code, allow the design to emerge based on the API’s implementation, and then use the source code to generate the API contract and documentation after the fact. In other words, design-first API development requires developers to write code that adheres to an established API contract, while code-first API development derives the API design and contract based on its source code implementation.
The design-first approach should be utilized for each required API when designing an API-first system. However, the design-first approach can also be used for individual APIs within systems that do not prioritize APIs as the core component (i.e., are not API-first).
Choosing an approach
While API-first and design-first are helpful frameworks that inform decision-making, the practical realities of software development rarely lead to purely API-first or purely design-first applications. Instead, teams should weigh the tradeoffs of each method with the understanding that real-world requirements will necessitate deviations from the established framework.
In general, API-first design is an effective approach for systems that rely on APIs for integration, scalability, or as a primary product offering. In addition, API-first should be considered for projects that involve substantial cross-team collaboration, are anticipated to require long-term system growth, or are developer-centric. Conversely, simpler systems or those with limited external dependencies may not require the upfront investment of API-first design. As mentioned above, each API within an API-first system should be implemented using the design-first approach.
Within a system that is not API-first, the decision to adopt the design-first approach can be made on a more granular level for each individual API. While many organizations benefit from the improved alignment and consistency of the design-first approach, projects in which rapid iteration is more important than long-term planning may be better suited to the flexibility and agility of code-first development. Examples of such projects could be prototypes, proofs-of-concept, or applications that must adhere to tight deadlines.
In the following sections, we examine eight best practices to help your team develop APIs effectively.
Prioritize API consumers during the design process
Prioritizing simplicity, consistency, and usability in API design ensures that developers can quickly adopt and use your API in their workflows. Let’s explore two effective strategies to accomplish this.
REST API endpoint naming
CRUD (Create, Read, Update, and Delete) operations are the fundamental actions that an API can perform on a resource. Because these actions are ubiquitous among REST APIs, endpoint naming conventions have emerged to facilitate consistent and intuitive client-server communication.
Following best practices for naming endpoints within REST APIs involves mapping CRUD operations to specific HTTP methods and defining the endpoint as the pluralized name of the requested resource. For example, the endpoints for a REST API managing a “user” resource would be:
- Create:
POST /api/users - Read:
GET /api/users/{id} - Update:
PUT or PATCH /api/users/{id} - Delete:
DELETE /api/users/{id}
Although these conventions were not established by a single body or at a single moment in history, they are now widely adopted across the industry to standardize API design practices.
Versioning
Properly versioning an API ensures backward compatibility while allowing for improvement, expansion, deprecation, and eventual sunsetting of features. Some common versioning techniques include the following.
URI versioning
URI versioning involves including the version number in the URI path:
https://api.example.com/v1/usersThis approach has the primary benefit of being clear and easy to understand for clients, with a straightforward structure that makes versioning explicit. When implementing URI versioning, it is important to keep version numbers concise (e.g., v1, v2, etc.) for clarity.
Query parameter versioning
In this approach, the version number is included as a query parameter:
https://api.example.com/users?version=1Query parameter versioning allows flexibility without altering the base URI structure, which makes it easier to adopt and test, particularly for existing APIs.
APIs that utilize query parameter versioning must ensure that clients explicitly provide the version number to avoid ambiguity. This can be accomplished by enforcing validation on the server through error responses for requests that do not include the required query parameters.
Header versioning
Header versioning means including the version in the request header:
Accept: application/vnd.myapi.v1+jsonThis approach keeps the URL clean and makes versioning invisible to users, which can benefit large or complex APIs. Use this method to manage versions more discretely, especially for highly granular or frequent changes.
Versioning best practices
Regardless of which versioning method you select, it is important to follow best practices:
- Document each version: Provide clear documentation for each version, outlining supported features, deprecated endpoints, and changes from prior versions.
- Communicate changes: Use changelogs, announcements, and migration guides to help clients prepare for updates.
- Limit version fragmentation: Minimize the number of active versions; too many can lead to increased maintenance and potential integration challenges.
- Automate testing for each version: Maintain tests for all versions to ensure that each works as expected, helping catch backward compatibility issues early.
- Address security vulnerabilities: API versions, especially older versions, should be regularly evaluated to prevent unauthorized access via URI enumeration or other means. If security issues are found, they must be promptly patched or the API version must be discontinued.
By applying these best practices, you can ensure that your API’s evolution remains smooth, predictable, and accessible for clients at all stages of integration.
Full-stack session recording
Learn more





Choose an appropriate architectural style
The choice of an API’s underlying architecture influences numerous factors, including the API’s scalability, security, maintainability, cost, and performance. Because of this, many modern distributed systems combine different architecture styles to optimize individual services, APIs, or subsystems.
For example, an e-commerce application could rely on a microservices subsystem for its product catalog and search capabilities while using an event-driven architecture to handle inventory and notifications. In this design, the high-traffic catalog and search services would benefit from horizontal scaling and independent deployments while the event-driven inventory and notifications subsystem facilitates real-time updates.
Let’s take a look at six common system architecture styles and how they can be used to build effective APIs.
Monolithic
In monolithic architectures, the API often serves as a unified entry point to a large, single application. The initial stages of developing monolithic API architectures tend to be more straightforward because there are fewer concerns about inter-service communication, consistency, and data management. Deploying a single monolithic application is also typically more straightforward than other, more modular system architectures. However, the scalability and maintainability challenges inherent to monolithic applications can make this architecture suboptimal for applications that anticipate significant growth or are maintained by larger development teams.
In general, monolithic architectures should be considered for relatively simple APIs that do not anticipate high traffic and are not expected to scale in the short term. This may include internal business systems or small CRUD applications. In addition, many startups and greenfield projects benefit from starting with a monolithic architecture before pulling pieces of functionality into separate services.
Microservices
In a microservices architecture, APIs enable communication between distinct, loosely coupled services. When developing an API based on a microservices architecture, developers are responsible for creating internal APIs to facilitate inter-service communication and external APIs to allow third parties to expose functionality to third parties. The added complexity of separate deployments and inter-service communication introduces challenges inherent to large, distributed systems architectures but also increases flexibility and resilience, as each microservice can be updated or scaled independently without disrupting the system.
Microservices have become an increasingly popular architecture choice for large-scale and dynamic systems. This architecture style will likely benefit APIs with varied functionality, high traffic, or granular scalability needs.
Event-driven
Many microservices architectures are also event-driven, meaning that they rely on a system of components that produce or consume events. In such a system, technologies like WebSockets or message queues facilitate communication between services. A core strength of an event-driven system is its ability to process data in real time. Events are emitted asynchronously, allowing external systems or APIs to react immediately to changes or triggers in the system.
This style is well-suited for applications where near-instantaneous responsiveness to data changes is essential, like IoT applications, notification services, or real-time analytics.
Serverless
Serverless architectures are comprised of small, stateless functions triggered by specific events. Serverless APIs are designed to be lightweight and scalable, with each function performing a discrete task and scaling automatically with demand. These APIs have a low operational cost, but they require careful design to handle the stateless nature of serverless computing.
The strengths of serverless architectures align well with both event-driven and microservices paradigms, so it is not uncommon for components of event-driven and microservices architectures to be implemented using serverless architectures. In addition, serverless architectures should be considered for APIs with variable traffic, short lifecycles, or low compute demands since these APIs do not require persistent infrastructure or long-running compute resources.
Edge computing
In edge computing, APIs interact with data and compute resources near the end-user or IoT device, reducing latency by processing data closer to its source. APIs in edge environments must be designed to handle distributed data and potentially offline functionality, offering robust handling of network fluctuations and localized processing.
This style is ideal for latency-sensitive applications, like gaming or IoT, where minimizing round-trip time to a central server can significantly improve the user experience.
Peer-to-peer (P2P)
In a peer-to-peer architecture, components interact directly with one another without relying on a central server. P2P systems require robust handling of decentralized authentication, data consistency, and network variability. Building P2P networks can be complex, as developers must handle node discovery and secure data exchange across potentially untrusted peers.
Because of this architecture’s decentralized nature, it is often used to build APIs for distributed storage (such as file sharing or cloud storage) as well as cryptocurrency and blockchain APIs.
Use RESTful or other appropriate paradigms
API paradigms—such as REST, GraphQL, and gRPC—are the design principles, patterns, and approaches used to structure how an API communicates with clients and other services. They determine how the API is built, how data is transmitted, and how client-server interactions are handled.
Each paradigm has strengths, and selecting the right one depends on your project's requirements. Whether REST’s simplicity, GraphQL’s flexibility, or gRPC’s performance, aligning your API design with your system’s goals is critical to building a successful interface.
Representational State Transfer (REST)
RESTful APIs are the most widely adopted approach. They use familiar HTTP methods like GET, POST, PUT, and DELETE to interact with resources. REST emphasizes stateless, resource-based interactions, where each request is independent and contains all the information needed to fulfill it.
import requests
url = 'https://jsonplaceholder.typicode.com/users'
try:
response = requests.get(url)
if response.status_code == 200:
users = response.json()
# Print out user information
for user in users:
print(f"Name: {user['name']}")
print(f"Email: {user['email']}")
print(f"City: {user['address']['city']}")
print("-" * 20)
else:
print(f"Failed to retrieve data. HTTP Status code: {response.status_code}")
except requests.exceptions.RequestException as e:
# Handle exceptions like connection errors or timeouts
print(f"An error occurred: {e}")
except ValueError as e:
# Handle JSON decoding errors
print(f"Error decoding JSON: {e}")
Sample Python RESTful API request
Interact with full-stack session recordings to appreciate how they can help with debugging
EXPLORE THE SANDBOX(NO FORMS)
REST APIs are simple and scalable. They are especially advantageous within web-based systems where resources can be easily mapped to endpoints like /users or /orders. However, alternative paradigms can offer greater flexibility and performance for applications requiring complex querying, real-time communication, or highly efficient data fetching.
GraphQL
The GraphQL paradigm allows clients to query only the needed data, making it highly efficient for use cases with complex data structures or requirements to minimize data transfer. This flexibility can improve client-side performance and simplify the interaction with diverse datasets.
import requests
url = 'https://countries.trevorblades.com/'
query = """
{
countries {
code
name
emoji
continent {
name
}
}
}
"""
headers = {'Content-Type': 'application/json'}
payload = {'query': query}
try:
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
data = response.json()
# Extract country information from the response
countries = data['data']['countries']
# Print out information for each country
# Limiting to the first 10 countries for brevity
for country in countries[:10]:
print(f"Country: {country['name']} ({country['code']})")
print(f"Emoji: {country['emoji']}")
print(f"Continent: {country['continent']['name']}")
print("-" * 20)
else:
print(f"Failed to retrieve data. HTTP Status code: {response.status_code}")
except requests.exceptions.RequestException as e:
print(f"An error occurred with the request: {e}")
except ValueError as e:
print(f"Error decoding JSON: {e}")
except KeyError as e:
print(f"Unexpected response structure: {e}")
Sample Python GraphQL query
gRPC
gRPC offers another communication option between high-performance systems or microservices. It provides efficient, binary communication through HTTP/2 and is ideal for low-latency, high-throughput applications. gRPC supports strong typing and allows bidirectional streaming, making it a powerful choice for services that require fast and reliable communication between components.
import grpc
import item_pb2
import item_pb2_grpc
def run():
try:
with grpc.insecure_channel('localhost:50051') as channel:
stub = item_pb2_grpc.ItemServiceStub(channel)
try:
response = stub.GetItem(item_pb2.ItemRequest(id=1))
print("Item received:")
print(f"ID: {response.id}")
print(f"Name: {response.name}")
print(f"Price: {response.price}")
except grpc.RpcError as e:
print(f"gRPC call failed: {e.code()} - {e.details()}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == '__main__':
run()
Sample Python gRPC query
Handle errors gracefully
A well-designed API should gracefully handle errors, ensuring that consumers can troubleshoot issues quickly and efficiently. One of the most critical aspects of error handling is using standardized HTTP status codes. By consistently applying codes like 200 for success, 400 for bad requests, 404 for not found, and 500 for internal server errors, you provide developers with clear indicators of what went wrong in their requests. This allows them to identify issues without guessing or digging into logs unnecessarily.
Equally important is returning descriptive and user-friendly error messages in the response body. Instead of vague or cryptic errors, provide messages that explain the problem in plain language, ideally with suggestions for resolving it. For example, consider the error response below:
HTTP/1.1 400 Bad Request
Content-Type: application/json
Content-Length: 123
Connection: close
Date: Sun, 06 Oct 2024 12:45:00 GMT
{
"error": {
"code": 400,
"message": "Invalid request: 'email' field is required.",
"details": {
"field": "email",
"issue": "missing"
}
}
}Example of a helpful error response
Instead of returning a 400 error with no context, this response includes a helpful message communicating the source of the error. Doing this helps the API’s developers resolve issues more quickly and also reduces back-and-forth communication between API consumers and support teams.
Organizations should adopt standardized and well-documented practices for handling different types of errors to ensure consistency across different development teams. While doing so requires an upfront time investment, organizations will likely save time in the long run. In addition, comprehensive, fine-grained, and declarative error handling ultimately results in APIs that are more transparent, accessible, and trustworthy to their consumers.
One click. Full-stack visibility. All the data you need correlated in one session
RECORD A SESSION FOR FREEDesign for security
Securing an API is critical to protecting sensitive data and maintaining the integrity of your system. Some essential practices include:
- Implementing robust authentication and authorization: Widely accepted standards like OAuth 2.0 or JSON Web Tokens (JWT) ensure that only authenticated users can access your API and provide a secure way to manage user sessions and token-based authentication. Once a user is authenticated, enforcing authorization permissions to limit access to specific resources based on roles or privileges is equally crucial.
- Validating inputs: Validate and sanitize incoming data to prevent attacks like SQL injection or cross-site scripting (XSS) and keep malicious input from reaching your backend systems. This is often done using third-party libraries or built-in framework features that validate input lengths, patterns, and data types or sanitize data by trimming whitespace or removing potentially harmful escape characters.
- Encrypting data: Transmit data with HTTPS using SSL/TLS to prevent eavesdropping or tampering and use robust encryption algorithms like AES-256 to store susceptible data (such as PII) at rest. Without this, sensitive data like passwords and personal information could be exposed to attackers.
- Implementing rate limiting: Controlling the number of requests a user can make within a certain period prevents malicious actors from overwhelming the system through denial-of-service (DoS) or brute force attacks. Rate limiting also provides several other benefits, such as ensuring fair and consistent API usage for all consumers and enhancing system stability.
- Properly configuring Cross-Origin Resource Sharing (CORS): Effective CORS policies prevent unauthorized domains from accessing your API and ensure that only trusted sources can make requests, adding another layer of security to your API. CORS policies are primarily enforced through HTTP headers, such as
Access-Control-Allow-Origin.
Optimize performance
Implement techniques that reduce server load and improve response times to ensure that your API performs efficiently, especially when handling large datasets. Doing so makes your API more scalable, responsive, and efficient. This section discusses four performance optimization techniques to help APIs handle increasing loads and large datasets while maintaining a smooth user experience.
Pagination
One of the most effective methods is pagination. Instead of returning all records simultaneously, paginating results allows clients to request data in manageable chunks. For example, the request below returns the second page of user records with a limit of 50 users per page. This means that user records 51-100 are returned from the database.
fetch('/users?page=2&limit=50');Pairing this with filtering and sorting options (e.g., /users?age=30&sort=asc) enables clients to query only the specific data they need. This reduces unnecessary data transfers and improves performance.
Caching
Another key strategy is leveraging caching headers like Cache-Control and ETag. Caching allows responses to be stored on the client side or intermediary servers so that repeated requests do not hit the backend unnecessarily. Using Cache-Control, you can define how long data can be stored before it needs to be refreshed. An example Cache-Control header might read:
Cache-Control: public, max-age=31536000, immutableEach directive in the header controls where, for how long, and how the resource should be cached:
publicindicates that the resource can be stored in any cache, such as a browser cache, CDN, or proxy.max-agedetermines how long the resource should be stored; in this case, for one year (31536000 seconds).immutablespecifies that the resource will not change and must not be revalidated during its lifetime in the cache.
For resources needing revalidation, the entity tag header (ETag) provides a mechanism for checking whether cached content has changed and determining whether the server should send new data. This significantly reduces server load and accelerates response times for repeat requests.
Compression
If your API returns large or complex responses, consider using compression algorithms like Gzip or Brotli to minimize the size of the data transferred over the network. The client indicates support for a given compression algorithm using the Accept-Encoding HTTP header.
Accept-Encoding: br, gzipThe server then includes the Content-Encoding header to indicate which compression algorithm has been applied.
Content-Encoding: brCompression ensures faster transmission for text-based files, large JSON responses, or large static assets hosted on content delivery networks or web servers.
Asynchronous processing
For long-running tasks, consider using asynchronous processing. Instead of making clients wait for a task to complete, you can process the job in the background and return a job ID to check the status later. This approach improves efficiency and enhances the user experience by preventing timeouts or slow responses for tasks that take longer to execute.
Use open standards and protocols
Adhere to established standards to build robust and widely compatible APIs. JSON has become the de facto format for structuring request and response bodies due to its simplicity and ease of use. Using JSON ensures that your API is easily consumable by various clients across different platforms. JSON is lightweight, human-readable, and language-independent, making it ideal for both frontend and backend systems to communicate efficiently.
A schema definition and validation tool like JSON Schema helps ensure that JSON data sent to and from your API adheres to the expected structure. JSON Schema allows you to define the structure, format, types, and constraints for the data your API accepts and returns. Once defined, the schema can be used to validate inputs and outputs, preventing common issues like malformed data or unexpected types and improving your API's security and reliability.
Standards like OpenAPI leverage JSON Schema to help describe the structure and behavior of APIs on a higher level. In OpenAPI specifications, JSON Schema definitions are used to describe the request bodies, response bodies, and parameters. These standards also allow for the automatic generation of documentation, client libraries, and server stubs, accelerating development and reducing errors.
Here is a basic example of OpenAPI standard documentation in YAML format:
openapi: 3.0.0
info:
title: User Management API
version: "1.0.0"
description: API for retrieving and deleting users.
servers:
- url: https://api.example.com/v1
description: Production server
paths:
/users/{userId}:
get:
summary: Get user by ID
description: Returns a single user
parameters:
- name: userId
in: path
required: true
schema:
type: string
responses:
"200":
description: A single user
content:
application/json:
schema:
$ref: '#/components/schemas/User'
"404":
description: User not found
delete:
summary: Delete user
description: Deletes a user by ID
parameters:
- name: userId
in: path
required: true
schema:
type: string
responses:
"204":
description: User deleted successfully
"404":
description: User not found
components:
schemas:
User:
type: object
properties:
id:
type: string
name:
type: string
email:
type: string
format: email
createdAt:
type: string
format: date-timeOpenAPI documentation example
As you can see, the documentation above describes a simple API with endpoints for retrieving user information and deleting a user. It also contains a schema definition for User objects to ensure consistency in JSON response bodies.
Document using a dedicated tool
A major challenge in effectively documenting systems is that static text alone cannot capture the behavior of the live system. Developers may have access to artifacts like system requirements docs, system design decisions, and architectural decision records via Google docs or internal wikis, but to see real system behavior, validate API calls, or test workflows across services, they must switch between multiple tools (API clients, APM dashboards, curl, logs, etc.). The result is that time is wasted context-switching, reproducing system states manually, and reconciling discrepancies between documentation and actual system behavior.
A more effective solution is to choose a tool that combines documentation with executable system context. For example, Multiplayer notebooks allow developers to embed live API calls, code snippets, and enriched text within a single environment. Teams can test endpoints, inspect responses, and validate workflows without switching tools.
In practice, you might first use a notebook block to make an API call:



To handle the response, you can chain the API block with an executable code block to parse and extract key fields like the method, host, and path:


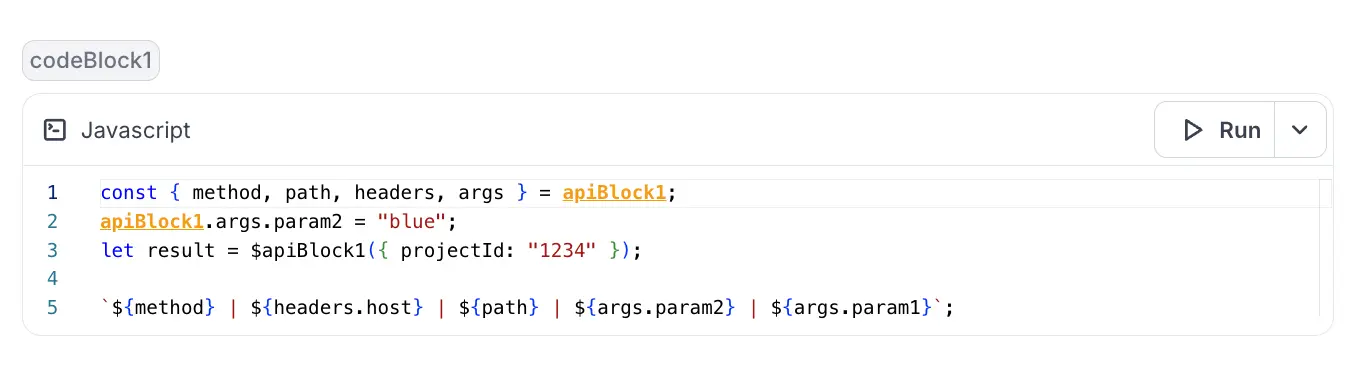
This approach provides a more effective way to observe how the endpoint behaves within the live system than static docs. To reduce overhead and help keep documentation accurate and up to date, notebooks can also be auto-generated using AI or from a full stack session recording.
Whatever your documentation solution, it is important for developers to have access to clear, up-to-date information about how to interact with your system. Document your endpoints, parameters, expected responses, and error codes thoroughly, and maintain consistency across your API documentation by adhering to the open standards discussed previously in this article.
Stop coaxing your copilot. Feed it correlated session data that’s enriched and AI-ready.
START FOR FREELast thoughts
The ultimate goal of API development is to deliver high-quality, fast, and well-structured APIs that facilitate smooth integrations, support current business needs, and are adaptable to future growth. By following best practices related to simplicity, performance, architecture, security, and documentation, you will be equipped to build APIs that are not only efficient but also easy to adopt and maintain. Remember these principles as you progress in your development projects to ensure that your APIs stand the test of time and meet the growing demands of modern applications.